标签:__ sds Redis len header 探究 源码 内存 字符串
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com
本文使用的Redis 5.0源码
概述
最近在通过 Redis 学 C 语言,不得不说,Redis的代码写的真的工整。这篇文章会比较全面的深入的讲解了Redis数据结构字符串的源码实现,希望大家能够从中学到点东西。
Redis 的字符串源码主要都放在了 sds.c 和 sds.h 这两个文件中。具体实现已经被剥离出来变成单独的库:https://github.com/antirez/sds。
Redis 的动态字符串结构如下图所示:
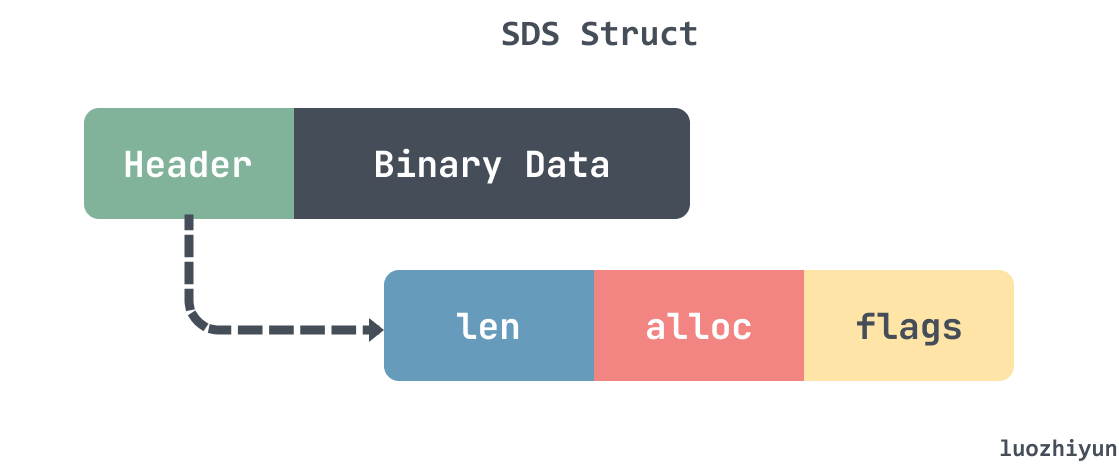
SDS 大致由两部分构成:header以及 数据段,其中 header 还包含3个字段 len、alloc、flags。len 表示数据长度,alloc 表示分配的内存长度,flags 表示了 sds 的数据类型。
在以前的版本中,sds 的header其实占用内存是固定8字节大小的,所以如果在redis中存放的都是小字符串,那么 sds 的 header 将会占用很多的内存空间。
但是随着 sds 的版本变迁,其实在内存占用方面还是做了一些优化:
- 在 sds 2.0 之前 header 的大小是固定的 int 类型,2.0 版本之后会根据传入的字符大小调整 header 的 len 和 alloc 的类型以便节省内存占用。
- header 的结构体使用
__attribute__修饰,这里主要是防止编译器自动进行内存对齐,这样可以减少编译器因为内存对齐而引起的 padding 的数量所占用的内存。
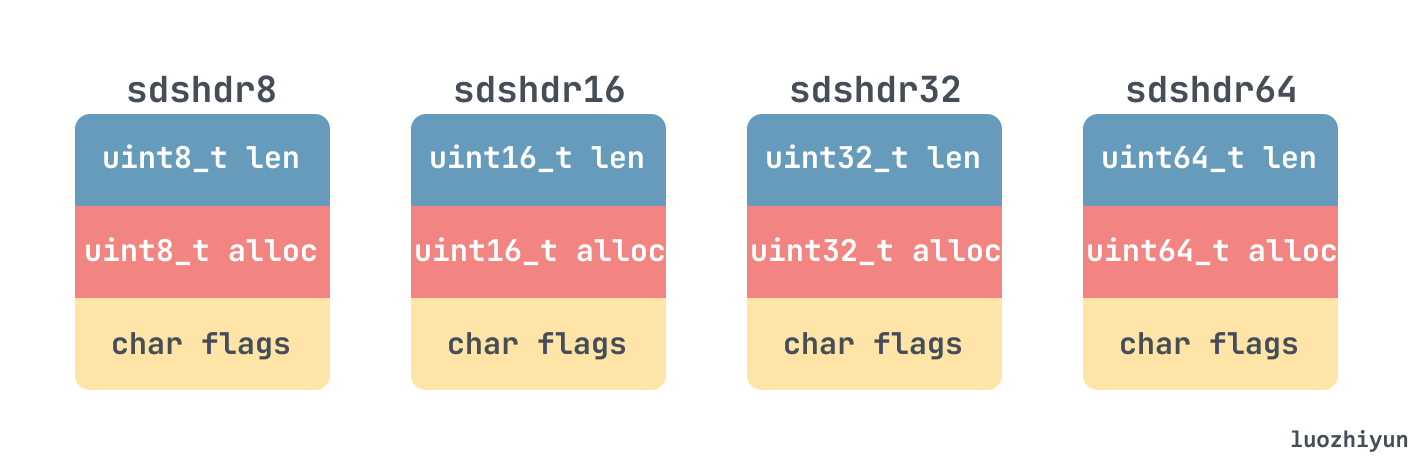
目前的版本中共定义了五种类型的 sds header,其中 sdshdr5 是没用的,所以没画:
源码分析
sds 的创建
sds 的创建主要有如下几个函数:
sds sdsnewlen(const void *init, size_t initlen);
sds sdsnew(const char *init);
sds sdsempty(void);
sds sdsdup(const sds s);
-
sdsnewlen 传入一个 C 的字符串进去,创建一个 sds 字符串,并且需要传入大小;
-
sdsnew 传入一个 C 的字符串进去,创建一个 sds 字符串,它里面实际上会调用
strlen(init)计算好长度之后调用 sdsnewlen; -
sdsempty 会创建一个空字符串 “”;
-
sdsdup 调用 sdsnewlen,复制一个已存在的字符串;
所以通过上面的创建可以知道,最终都会调用 sdsnewlen 来创建字符串,所以我们看看这个函数具体怎么实现。
sdsnewlen
其实对于一个字符串对象的创建来说,其实就做了三件事:申请内存、构造结构体、字符串拷贝到字符串内存区域中。下面我们看一下 Redis 的具体实现。
申请内存
sds sdsnewlen(const void *init, size_t initlen) {
void *sh; //指向SDS结构体的指针
sds s; //sds类型变量,即char*字符数组
char type = sdsReqType(initlen); //根据数据大小获取sds header 类型
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type); // 根据类型获取sds header大小
unsigned char *fp; /* flags pointer. */
assert(hdrlen+initlen+1 > initlen); /* Catch size_t overflow */
sh = s_malloc(hdrlen+initlen+1); //新建SDS结构,并分配内存空间,这里加1是因为需要在最后加上\0
...
return s;
}
在内存申请之前,需要做的事情有以下几件:
- 因为 sds 会根据传入的大小来设计 header 的类型,所以需要调用 sdsReqType 函数根据 initlen 获取 header 类型;
- 然后调用 sdsHdrSize 根据 header 类型获取 header 占用的字节数;
- 最后调用 s_malloc 根据 header 长度和字符串长度分配内存,这里需要加1是因为在 c 里面字符串是以
\0结尾的,为了兼容 c 的字符串格式。
既然说到了 header 类型,那么我们先来看看 header 的类型定义:
struct __attribute__ ((__packed__)) sdshdr8 { // 占用 3 byte
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 { // 占用 5 byte
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 { // 占用 9 byte
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 { // 占用 17 byte
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
在这里 __attribute__ 是用来防止内存对齐用的,否则也会浪费一些存储空间。关于内存对齐相关的知识,我在 《Go中由WaitGroup引发对内存对齐思考》 这篇文章里面也讲解过了,知识点是通用的,感兴趣的可以回过去看看。
看了上面的定义之后,我们自然而然的就可以想到,Redis 会根据传入的大小判断生成的 sds header 头类型:
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5) // 小于 32
return SDS_TYPE_5;
if (string_size < 1<<8) // 小于 256
return SDS_TYPE_8;
if (string_size < 1<<16) // 小于 65,536
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
#else
return SDS_TYPE_32;
#endif
}
可以看到 sdsReqType 是根据传入的字符串长度来判断字符类型。
构造结构体
对于Redis来说,如果没用过C语言的同学,会觉得它这里构造结构体的方式比较 hack。首先它是直接根据需要的内存大小申请一块内存,然后初始化头结构的指针指向的位置,最后为头结构的指针设值。
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
sds sdsnewlen(const void *init, size_t initlen) {
...
sh = s_malloc(hdrlen+initlen+1); // 1.申请内存,这里长度加1是为了在最后面存放一个 \0
if (sh == NULL) return NULL;
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);// 2.将内存的值都设置为0
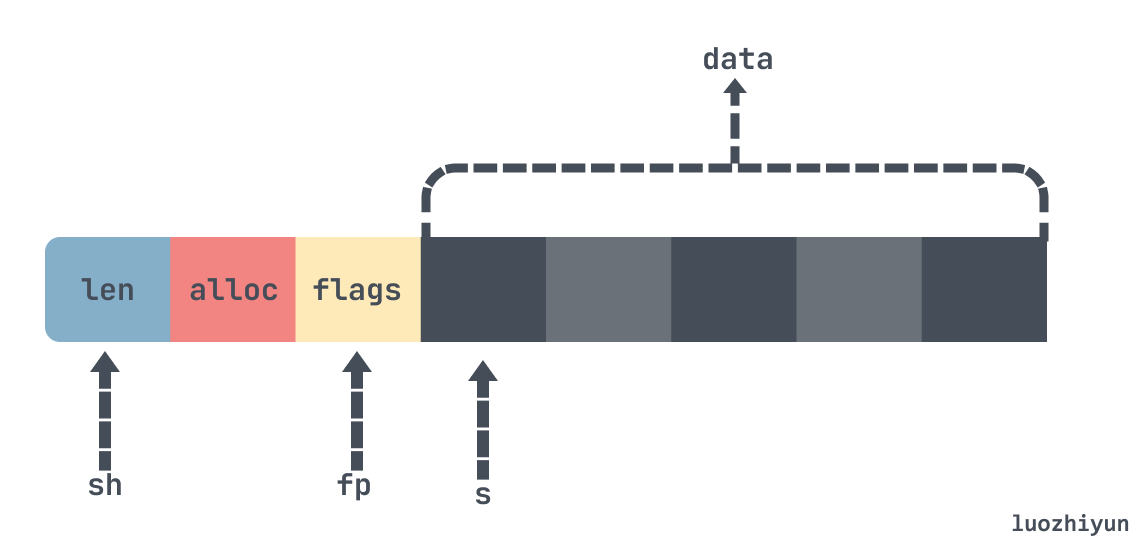
s = (char*)sh+hdrlen; //3.将s指针指向数据起始位置
fp = ((unsigned char*)s)-1; //4.将fp指针指向sds header的flags字段
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); //5.构造sds结构体header
sh->len = initlen; // 初始化 header len字段
sh->alloc = initlen; // 初始化 header alloc字段
*fp = type; // 初始化 header flag字段
break;
}
...
}
...
return s;
}
上面的过程我已经标注清楚了,可能直接看代码比较难理解这里的头结构体构造的过程,我下面用一张图表示一下指针指向的位置:
字符串拷贝
sds sdsnewlen(const void *init, size_t initlen) {
...
if (initlen && init)
memcpy(s, init, initlen); //将要传入的字符串拷贝给sds变量s
s[initlen] = '\0'; //变量s末尾增加\0,表示字符串结束
return s;
}
memcpy 函数会逐个字节的将字符串拷贝到 s 对应的内存区域中。
sdscatlen 字符串追加
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); // 获取字符串 len 大小
//根据要追加的长度len和目标字符串s的现有长度,判断是否要增加新的空间
//返回的还是字符串起始内存地址
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
// 将新追加的字符串拷贝到末尾
memcpy(s+curlen, t, len);
// 重新设置字符串长度
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
在这个字符串追加的方法里,其实把空间检查和扩容封装在了 sdsMakeRoomFor 函数中,它里面所要做的就是:
- 有没有剩余空间,有的话直接返回;
- 没有剩余空间,那么需要扩容,扩容多少?
- 字符串是否可以在原来的位置追加空间,还是需要重新申请一块内存区域。
那么下面我把 sdsMakeRoomFor 函数分为两部分来看:扩容、内存申请。
扩容
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s); //这里是用 alloc-len,表示可用资源
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
if (avail >= addlen) return s; // 如果有空间剩余,那么直接返回
len = sdslen(s); // 获取字符串 len 长度
sh = (char*)s-sdsHdrSize(oldtype); //获取到header的指针
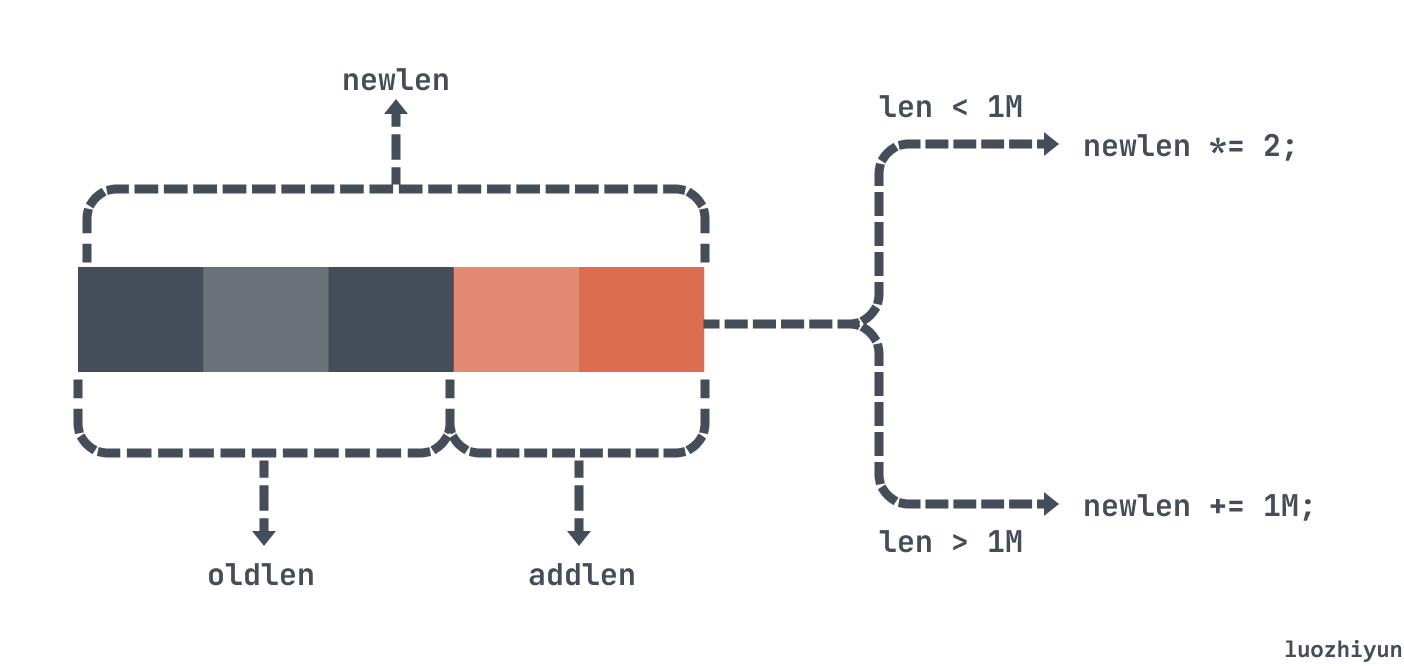
newlen = (len+addlen); // 新的内存空间
if (newlen < SDS_MAX_PREALLOC) //如果小于 1m, 那么存储空间直接翻倍
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; //超过了1m,那么只会多增加1m空间
...
return s;
}
对于扩容来说,首先会看一下空间是否足够,也就是根据 alloc-len 判断, 有剩余空间直接返回。
然后 Redis 会根据 sds 的大小不同来进行扩容,如果 len+addlen空间小于 1m,那么新的空间直接翻倍;如果 len+addlen空间大于 1m ,那么新空间只会增加 1m。
内存申请
sds sdsMakeRoomFor(sds s, size_t addlen) {
...
type = sdsReqType(newlen); // 根据新的空间占用计算 sds 类型
hdrlen = sdsHdrSize(type); // header 长度
if (oldtype==type) { // 和原来header一样,那么可以复用原来的空间
newsh = s_realloc(sh, hdrlen+newlen+1); // 申请一块内存,并追加大小
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
//如果header 类型变了,表示内存头变了,那么需要重新申请内存
//因为如果使用s_realloc只会向后追加内存
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh); // 释放掉原内存
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);//重新设置alloc字段
return s;
}
在内存申请上,Redis 分为两种情况,一种是 sds header 类型没变,那么可以直接调用 realloc在原有内存后面追加新的内存区域即可;
另一种是 sds header 类型发生了变化,这里一般是 header 占用的空间变大了,因为 realloc 无法向前追加内存区域,所以只能调用 malloc 重新申请一块内存区域,然后通过 memcpy 将字符串拷贝到新的地址中去。
总结
通过这篇文章,我们深入学习到 Redis 的字符串是怎么实现,得知它通过版本的更迭做了哪些改变,大家可以自己拿 sds 和自己熟悉的语言的字符串实现做个对比,看看实现上有啥差异,哪个更好。
Reference
https://redis.io/docs/reference/internals/internals-sds/
https://github.com/antirez/sds

标签:__,sds,Redis,len,header,探究,源码,内存,字符串 来源: https://www.cnblogs.com/luozhiyun/p/16388125.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。