标签:index 使用 规范 查询 索引 SELECT SQL 优化 select
SQL规范及优化办法
环境恢复
本例中的数据库和相关的文件下载地址为:数据库规范相关脚本下载地址
下载完脚本后,请使用下面的命令在本地数据库中恢复相关的数据表

练习题目:
有学生表和成绩表两个表,表的数据比较大,现在要查出没有成绩的学生的相关信息,请写出对应的合理SQL,要求SQL执行时间在毫秒级。
sql规范整体说明
sql规范的核心是不需要很复杂数据库执行的操作,因为数据库在高并发下压力很大会导致整个系统出问题,复杂的操作改由代码完成,规范核心如下:
- 不写两张表以上的关联查询(后台部分频次很低的需求,经过上级同意的例外)
- 严禁使用外键、存储过程和触发器
- 不使用not in 或者exist相关的语句
- where 后面的查询条件a=b中,a这段不能有mysql函数,会导致索引失效
- 合理使用索引,必须的时候多个字段加联合索引,有索引的字段在insert后尽量不对这个字段update(是这个字段更新,其他非索引字段可以随便update),因为这个时候索引会重排,
规范范例
多表关联解决方法
- 自己实现逻辑,里面最多是两张表管理查询,多次查询,然后用代码来整合在一起
- 后台多表查询合理优化,确保执行效率是毫秒级就行
not in和exist
- 用left join或者right join来解决
外键,存储过程和触发器解决
- 外键的完整性用我们的代码来解决,插入或者更新前验证相关字段
- 存储过程就是一堆sql,用代码直接解决就行
- 触发器用两个解决办法:
- 一般可以接受一定演示,用定时后台任务来解决
- 实时可以让插入的同时发个消息给我们,用消息中间件或者队列来解决
其他范例
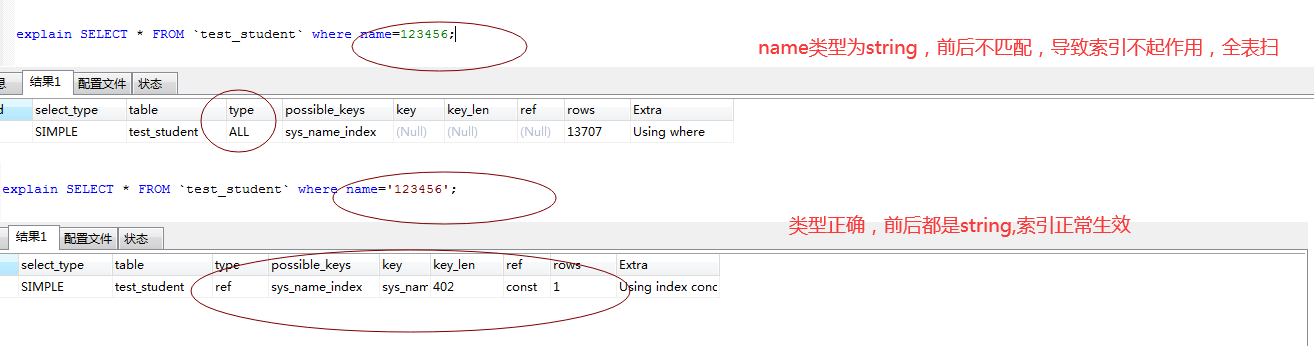
a=b查询条件中a不能有函数
如下,查询在今日创建的同学:
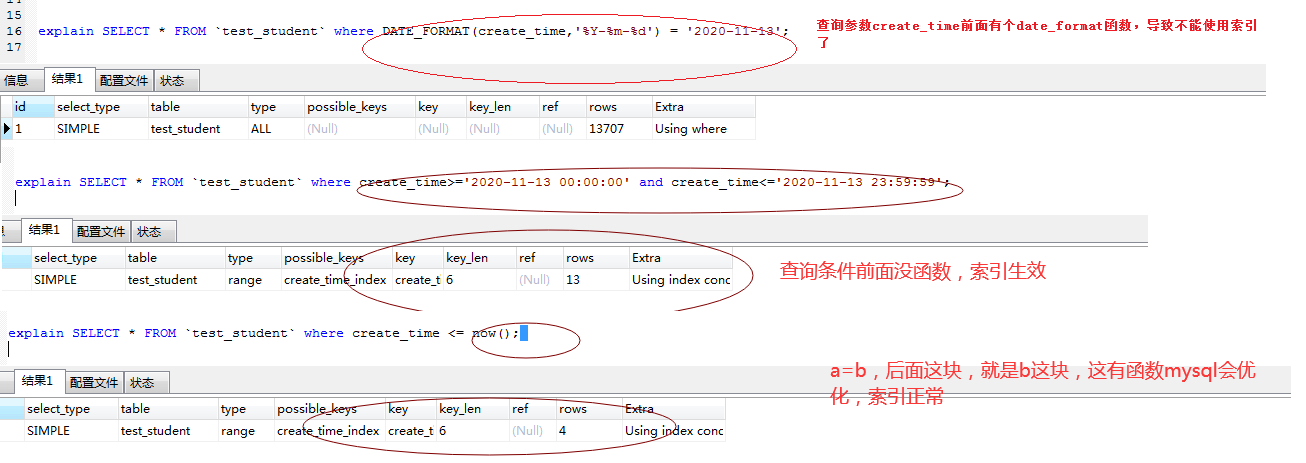
a=b类型不匹配会导致索引失效
可以使用in,如下:
select * from test_student where name in ('学生1','学生2','学生3');
in里面可以使用多个元素,同时查询多个数据,这个时候注意in里面一般不要超过1000个元素
用explain分析sql执行效率
explain用来分析sql查询语句的执行效率,desc命令同样的效果。
语法:explain 查询语句
举个栗子:explain select * from news;
输出:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
下面对各个属性进行了解:
-
id:这是SELECT的查询序列号
-
select_type:select_type就是select的类型,可以有以下几种:
- SIMPLE:简单SELECT(不使用UNION或子查询等)
- PRIMARY:最外面的SELECT
- UNION:UNION中的第二个或后面的SELECT语句
- DEPENDENT UNION:UNION中的第二个或后面的SELECT语句,取决于外面的查询
- UNION RESULT:UNION的结果。
- SUBQUERY:子查询中的第一个SELECT
- DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询
- DERIVED:导出表的SELECT(FROM子句的子查询)
-
table:显示这一行的数据是关于哪张表的
-
type:这列最重要,显示了连接使用了哪种类别,有无使用索引,是使用Explain命令分析性能瓶颈的关键项之一。
结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
-
possible_keys:列指出MySQL能使用哪个索引在该表中找到行
-
key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
-
key_len:显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好
-
ref:显示使用哪个列或常数与key一起从表中选择行。
-
rows:显示MySQL认为它执行查询时必须检查的行数。
-
Extra:包含MySQL解决查询的详细信息,也是关键参考项之一。
-
Distinct
一旦MYSQL找到了与行相联合匹配的行,就不再搜索了 -
Not exists
MYSQL 优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了 -
Range checked for each
-
Record(index map:#)
没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一 -
Using filesort
看 到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来 排序全部行 -
Using index
列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表 的全部的请求列都是同一个索引的部分的时候 -
Using temporary
看到这个的时候,查询需要优化了。这 里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上 -
Using where
使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index, 这就会发生,或者是查询有问题
-
注意:当type 显示为 “index” 时,并且Extra显示为“Using Index”, 表明使用了覆盖索引。
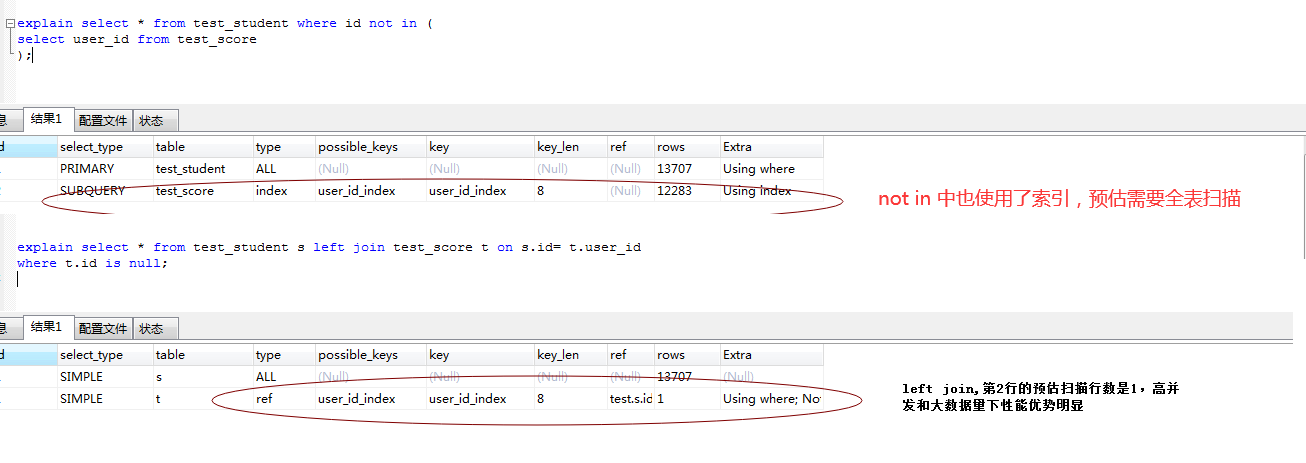
本例解决办法
按照正常not in来说,写法应该是:
select * from test_student where id not in (
select user_id from test_score
);
采用left join来解决not in:
select * from test_student s left join test_score t on s.id= t.user_id
where t.id is null;
本例中,因为数据量不大,并且mysql本身对sql也有优化,所以left join性能并没有特别的体现,但是在高并发情况或者大数据量情况下,not in性能会快速下降
用explain查看预估扫描行数可以看到差别:
【备注】
在数据量比较小(如本例)的情况下,索引和优秀写法的性能差别并不大,但是在数据量比较大(数十万及更多,或者中间有大字段,例如text)的情况下,不规范写法的性能会快速下降,所以要遵守规范,这也是互联网与其他在sql方面的显著差别之一。
标签:index,使用,规范,查询,索引,SELECT,SQL,优化,select 来源: https://www.cnblogs.com/faetbwac/p/16380752.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。