标签:... target Sentiment slices Attention vector memory Network
文章目录
前提
Motivation
-
在当时之前的工作中,大家都已经认识到要做细粒度情感分析,结合上下文很重要。
但LSTM、TD-LSTM 等方法存在缺陷,用该方法捕捉到一个远离目标的情感特征之后,它需要逐字逐句地向目标传播这个特征,在这种情况下,最后得到的整个句子的特征包含很少的目标信息。例如 the feature “cost-effective” for “the phone” in “My overall feeling is that the phone, after using it for three months and considering its price, is really cost-effective.”。
为了解决上面的问题,虽然有的方法(例如 ATAE-LSTM等方法)利用了 Attention mechanism,并且也取得不错的效果,但是可以看出来该方法是基于单一注意的方法,因为只是单一注意,所以如果是几个词的 embedding vector 作为该 Attention mechanism 中的 q,那么会只注意多个单词而可能掩盖了每个出席单词的特征(这一点在 《Interactive Attention Networks for Aspect-Level Sentiment Classification》这篇论文的 Motivation 中也有体现,即 target 不一定只能是一个词,而如果 target 是多个词,那么也一定有重要性的高低不同,如果没用的应对处理可能就会掩盖有的重要词的信息)。
-
有的句子的结构比较复杂,仅仅用 LSTM 来建模得不到正确的表示。例如:“Except Patrick, all other actors don’t play well”,如果用 LSTM 来对此句中的 target “Patrck” 做情感分类,那么 LSTM 会更多地考虑离最后更近的 “don’t play well”,而更少的考虑 “Except”,这样实际上等于没有联系地考虑前后两部分,从而得到结果为 negtive,使得预测错误。
同样使用单一的 Attention 也可能无法解决该问题,因为单一的 Attention model 还是比较简单,所以在对多个词进行 attention 操作时可能会丢失一些词比较重要的信息。
方法概述
- 通过一个 BLSTM 得到每个词对应的 Memory。
- 根据每个 memory slice 对应的 word 与 target 的相对位置给 memory slices 赋予权重,并计算得到乘以权重之后的 memory slices 。
- 利用多层 Attention 来选择合适的 memory slices。
- 利用 GRU(因为比起 RNN 更轻量级)来整合上一步得到的结果。
- 将上面得到的结果用于最后预测。
整体框架图如下
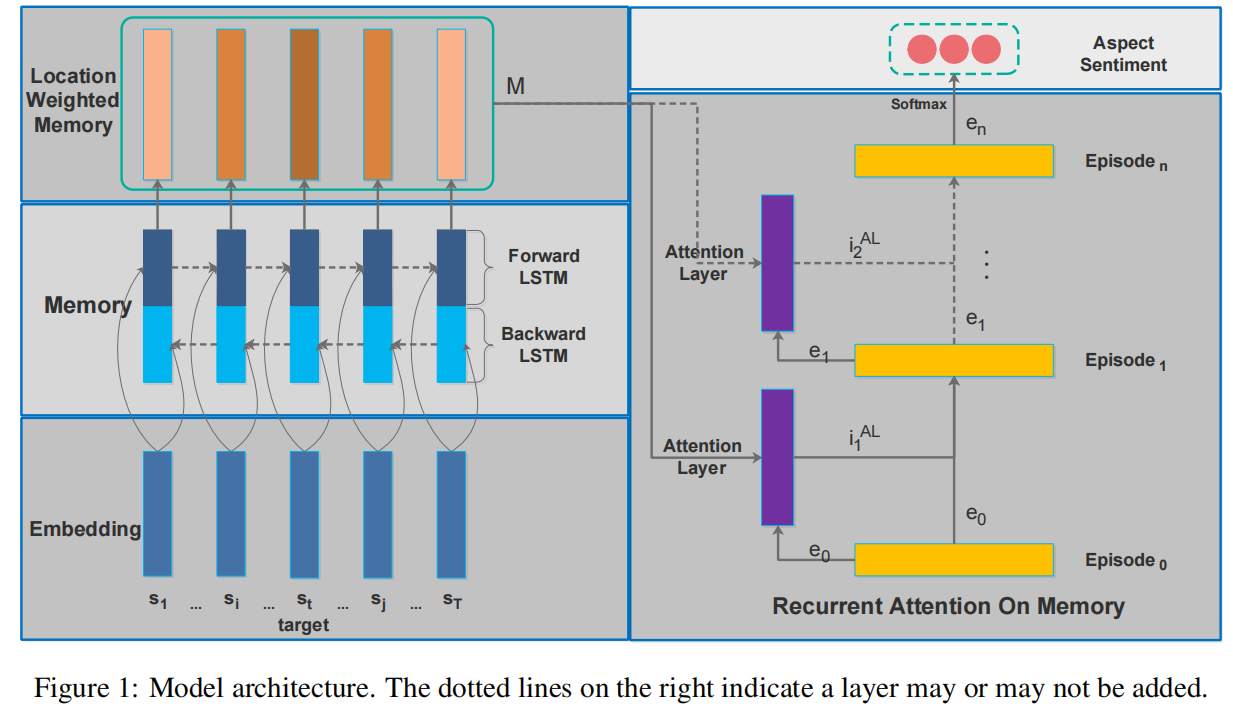
方法详述
将输入的句子表示为 S = { s 1 , … , s τ − 1 , s τ , s τ + 1 , … , s T } =\{s_1,…,s_{τ-1},s_τ,s_{τ+1},…,s_T\} ={s1,…,sτ−1,sτ,sτ+1,…,sT} ,其中 target 为 s τ s_τ sτ
Input Embedding
使用 Glove,得到每个词对应的 embedding vector { v 1 , . . . , v t , . . . , v T } \{v1,...,v_t,...,v_T\} {v1,...,vt,...,vT} ,其中 v t ∈ R d v_t ∈ R^d vt∈Rd。
(值得注意的是,可以微调 embedding 使得其还可以表示一部分除相似性的信息。)
BLSTM for Memory Building
之前的一些相关工作中都是直接将 embedding vector 存入 memory 中,但是这样其实只存储了词向量的相似性信息,而对于一个个具体的句子来说,每个词肯定会包含该句话特定的上下文语义。所以,作者选择将 embedding vector 作为输入放入 BLSTM 中,得到每个词的隐状态作为对应的 memory slice。
这样可以得到最后的 memory slices,即 M ∗ = m 1 ∗ , . . . , m t ∗ , . . . , m T ∗ M^* = {m_1^*,...,m_t^*,...,m_T^*} M∗=m1∗,...,mt∗,...,mT∗,其中 m t ∗ = ( h t L → , h t L ← ) ∈ R h → L + h ← L m_t^* = (\overset{→}{h_t^L},\overset{←}{h_t^L}) ∈ R^{\overset{→}{h}_L + \overset{←}{h}_L} mt∗=(htL→,htL←)∈Rh→L+h←L ,其中 h t L → , h t L ← \overset{→}{h_t^L},\overset{←}{h_t^L} htL→,htL← 分别为第 t 个 word 的 embedding vector 在第 L L L 层 BLSTM 中的隐状态。
Position-Weighted Memory
上部分得到的每个 memory slice 得来的流程都是相同的,这会导致,如果要对句子中不同的 target 做情感分类,那么这些 memory slices 在任务中的作用是没有去别的。
所以基于一般离 target 更近的词更能反应其情感极性的观察,作者给每个 Memory slice 计算了位置权重,并根据此权重计算最后带有位置信息的 memory slices。
每个位置权重
w
t
w_t
wt 的计算公式如下:
w
t
=
1
−
∣
t
−
τ
∣
t
m
a
x
(7)
w_t = 1-\frac{|t-τ|}{t_{max}} \tag7
wt=1−tmax∣t−τ∣(7)
其中
t
m
a
x
t_{max}
tmax 可以看作整个句子的截断长度。可以从该式中看出,词
t
t
t 离 target
τ
τ
τ 越近其权重越大。并且作者定义其中
u
t
=
∣
t
−
τ
∣
t
m
a
x
u_t = \frac{|t-τ|}{t_{max}}
ut=tmax∣t−τ∣。(PS:如果 target 中包含多个词的话,那么
τ
τ
τ 的大小取 target 最左或最右一个词的位置,具体怎么取取决于
w
t
w_t
wt 在 target 的哪一边——在左边就取最左。)
所以最后的 memory slices 为 M = m 1 , . . . , m t , . . . , m T M = {m_1,...,m_t,...,m_T} M=m1,...,mt,...,mT 其中 $m_t = (w_t·m_t^*,u_t) ∈ R^{\overset{→}{d_L}+\overset{←}{d_L} + 1} $ ,可以发现,作者还在每个 memory slice中拼接了相对位置信息 u t u_t ut。
Recurrent Attention on Memory
准备工作已经做完,接下来需要解决两个问题:
- 怎么用 memory slices,具体来说是怎么决定哪些是对情感分类更重要的信息。
- 选出合适的 memory slices 后怎么合理利用它们来帮助任务。
作者的相应的应对方法如下:
- 用多层 Attention 来完成,以确保通过全面、细致的考虑得到如何选择 memory slices 的方案。
- 利用 GRU 对 Attention 的结果进行整合。
这部分我不分开解释了,先看图,这部分是上面整个模型图的右半部分:
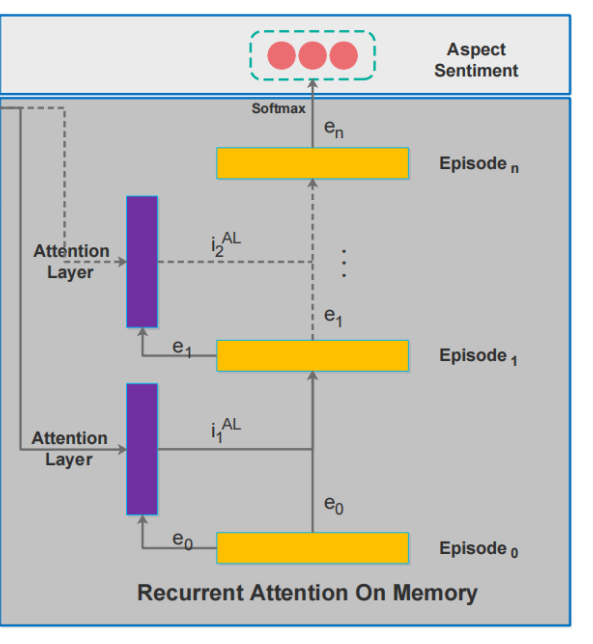
首先要知道,memory slices 通过 Attention Layer 后其实就是一个向量,而 e i − 1 e_{i-1} ei−1 可以看作是 Attention Layer 的查询向量。现在我们可以将图中的紫色部分就当成是一个 vector(甚至看成是一个 embedding vector),而黄色部分就是 GRU 部分(简化版 RNN)。所以这幅图就可以看成是多个向量送入 GRU 中,每步得到一个隐层表示 e i e_i ei -> 换句说,这样的形式不就相当于平时大家将一个 sequence 送入 RNN 中得到最后的 隐层表示么,只不过这里的 embedding vector 换成了 Attention 后得到的 vector。
Output and Model Training
这部分无需多说,作者就是用了交叉熵来完成的。
不懂
- Attention 机制一般可以有效表示多少个词的混合信息。
Training
这部分无需多说,作者就是用了交叉熵来完成的。
不懂
- Attention 机制一般可以有效表示多少个词的混合信息。
- 句子中单词的个数不应该是整数么?为什么还需要截断长度。
标签:...,target,Sentiment,slices,Attention,vector,memory,Network 来源: https://blog.csdn.net/wtfloser/article/details/115318327
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。