标签:教程 LightGBM python Histogram df 算法 train test wise
安装
pip install lightgbm- 1
- 1
gitup网址:https://github.com/Microsoft/LightGBM
中文教程
http://lightgbm.apachecn.org/cn/latest/index.html
lightGBM简介
xgboost的出现,让数据民工们告别了传统的机器学习算法们:RF、GBM、SVM、LASSO……..。现在微软推出了一个新的boosting框架,想要挑战xgboost的江湖地位。
顾名思义,lightGBM包含两个关键点:light即轻量级,GBM 梯度提升机。
LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树。它可以说是分布式的,高效的,有以下优势:
更快的训练效率
低内存使用
更高的准确率
支持并行化学习
可处理大规模数据
如果你觉得这篇文章看起来稍微还有些吃力,或者想要系统地学习人工智能,那么推荐你去看床长人工智能教程。非常棒的大神之作,教程不仅通俗易懂,而且很风趣幽默。点击这里可以查看教程。
xgboost缺点
其缺点,或者说不足之处:
每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
预排序方法(pre-sorted):首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。其次时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
lightGBM特点
以上与其说是xgboost的不足,倒不如说是lightGBM作者们构建新算法时着重瞄准的点。解决了什么问题,那么原来模型没解决就成了原模型的缺点。
概括来说,lightGBM主要有以下特点:
基于Histogram的决策树算法
带深度限制的Leaf-wise的叶子生长策略
直方图做差加速
直接支持类别特征(Categorical Feature)
Cache命中率优化
基于直方图的稀疏特征优化
多线程优化
前2个特点使我们尤为关注的。
Histogram算法
直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略:每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
Leaf-wise的缺点:可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
xgboost和lightgbm
决策树算法
XGBoost使用的是pre-sorted算法,能够更精确的找到数据分隔点;
- 首先,对所有特征按数值进行预排序。
- 其次,在每次的样本分割时,用O(# data)的代价找到每个特征的最优分割点。
- 最后,找到最后的特征以及分割点,将数据分裂成左右两个子节点。
优缺点:
这种pre-sorting算法能够准确找到分裂点,但是在空间和时间上有很大的开销。
- i. 由于需要对特征进行预排序并且需要保存排序后的索引值(为了后续快速的计算分裂点),因此内存需要训练数据的两倍。
- ii. 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
LightGBM使用的是histogram算法,占用的内存更低,数据分隔的复杂度更低。
其思想是将连续的浮点特征离散成k个离散值,并构造宽度为k的Histogram。然后遍历训练数据,统计每个离散值在直方图中的累计统计量。在进行特征选择时,只需要根据直方图的离散值,遍历寻找最优的分割点。
Histogram 算法的优缺点:
- Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,甚至会好一些。原因在于decision tree本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合。
- 时间上的开销由原来的
O(#data * #features)降到O(k * #features)。由于离散化,#bin远小于#data,因此时间上有很大的提升。 - Histogram算法还可以进一步加速。一个叶子节点的Histogram可以直接由父节点的Histogram和兄弟节点的Histogram做差得到。一般情况下,构造Histogram需要遍历该叶子上的所有数据,通过该方法,只需要遍历Histogram的k个捅。速度提升了一倍。
决策树生长策略
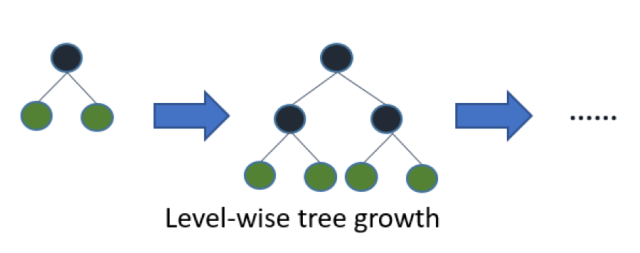
XGBoost采用的是按层生长level(depth)-wise生长策略,如Figure 1所示,能够同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合;但不加区分的对待同一层的叶子,带来了很多没必要的开销。因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
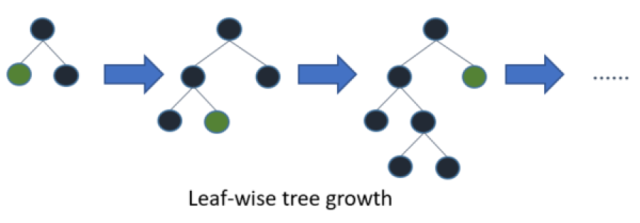
LightGBM采用leaf-wise生长策略,如Figure 2所示,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
网络通信优化
XGBoost由于采用pre-sorted算法,通信代价非常大,所以在并行的时候也是采用histogram算法;LightGBM采用的histogram算法通信代价小,通过使用集合通信算法,能够实现并行计算的线性加速。
LightGBM支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化one-hotting特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
lightGBM调参
所有的参数含义,参考:http://lightgbm.apachecn.org/cn/latest/Parameters.html
调参过程:
(1)num_leaves
LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth。
大致换算关系:num_leaves = 2^(max_depth)
(2)样本分布非平衡数据集:可以param[‘is_unbalance’]=’true’
(3)Bagging参数:bagging_fraction+bagging_freq(必须同时设置)、feature_fraction
(4)min_data_in_leaf、min_sum_hessian_in_leaf
sklearn接口形式的LightGBM示例
这里主要以sklearn的使用形式来使用lightgbm算法,包含建模,训练,预测,网格参数优化。
import lightgbm as lgbimport pandas as pdfrom sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import GridSearchCVfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import make_classification# 加载数据print('Load data...')iris = load_iris()data=iris.datatarget = iris.targetX_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2)# df_train = pd.read_csv('../regression/regression.train', header=None, sep='\t')# df_test = pd.read_csv('../regression/regression.test', header=None, sep='\t')# y_train = df_train[0].values# y_test = df_test[0].values# X_train = df_train.drop(0, axis=1).values# X_test = df_test.drop(0, axis=1).valuesprint('Start training...')# 创建模型,训练模型gbm = lgb.LGBMRegressor(objective='regression',num_leaves=31,learning_rate=0.05,n_estimators=20)gbm.fit(X_train, y_train,eval_set=[(X_test, y_test)],eval_metric='l1',early_stopping_rounds=5)print('Start predicting...')# 测试机预测y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)# 模型评估print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)# feature importancesprint('Feature importances:', list(gbm.feature_importances_))# 网格搜索,参数优化estimator = lgb.LGBMRegressor(num_leaves=31)param_grid = { 'learning_rate': [0.01, 0.1, 1], 'n_estimators': [20, 40]}gbm = GridSearchCV(estimator, param_grid)gbm.fit(X_train, y_train)print('Best parameters found by grid search are:', gbm.best_params_)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 1
原生形式使用lightgbm
# coding: utf-8# pylint: disable = invalid-name, C0111import jsonimport lightgbm as lgbimport pandas as pdfrom sklearn.metrics import mean_squared_errorfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import make_classificationiris = load_iris()data=iris.datatarget = iris.targetX_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2)# 加载你的数据# print('Load data...')# df_train = pd.read_csv('../regression/regression.train', header=None, sep='\t')# df_test = pd.read_csv('../regression/regression.test', header=None, sep='\t')## y_train = df_train[0].values# y_test = df_test[0].values# X_train = df_train.drop(0, axis=1).values# X_test = df_test.drop(0, axis=1).values# 创建成lgb特征的数据集格式lgb_train = lgb.Dataset(X_train, y_train)lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)# 将参数写成字典下形式params = { 'task': 'train', 'boosting_type': 'gbdt', # 设置提升类型 'objective': 'regression', # 目标函数 'metric': {'l2', 'auc'}, # 评估函数 'num_leaves': 31, # 叶子节点数 'learning_rate': 0.05, # 学习速率 'feature_fraction': 0.9, # 建树的特征选择比例 'bagging_fraction': 0.8, # 建树的样本采样比例 'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging 'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息}print('Start training...')# 训练 cv and traingbm = lgb.train(params,lgb_train,num_boost_round=20,valid_sets=lgb_eval,early_stopping_rounds=5)print('Save model...')# 保存模型到文件gbm.save_model('model.txt')print('Start predicting...')# 预测数据集y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)# 评估模型print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 1
标签:教程,LightGBM,python,Histogram,df,算法,train,test,wise 来源: https://blog.csdn.net/qq_45093246/article/details/91420665
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。