标签:00 多处理器 操作系统 thread void 编程 线程 Hello cur
参考教程: 《操作系统: 设计与实现》南京大学公开课、《深入理解计算机系统》、《操作系统概念》
这一周的主题是并发,而这一篇作为主题的开篇,从操作系统的角度看待并发,之后会深入到Linux系统、Windows系统和相关程序语言上进行分析和实践,内容可能包括: 基于Linux源码分析互斥锁的实践,Windows多线程应用程序的开发,Go语言的并发模式
那么欢迎来到并发的世界 ฅ՞•ﻌ•՞ ต
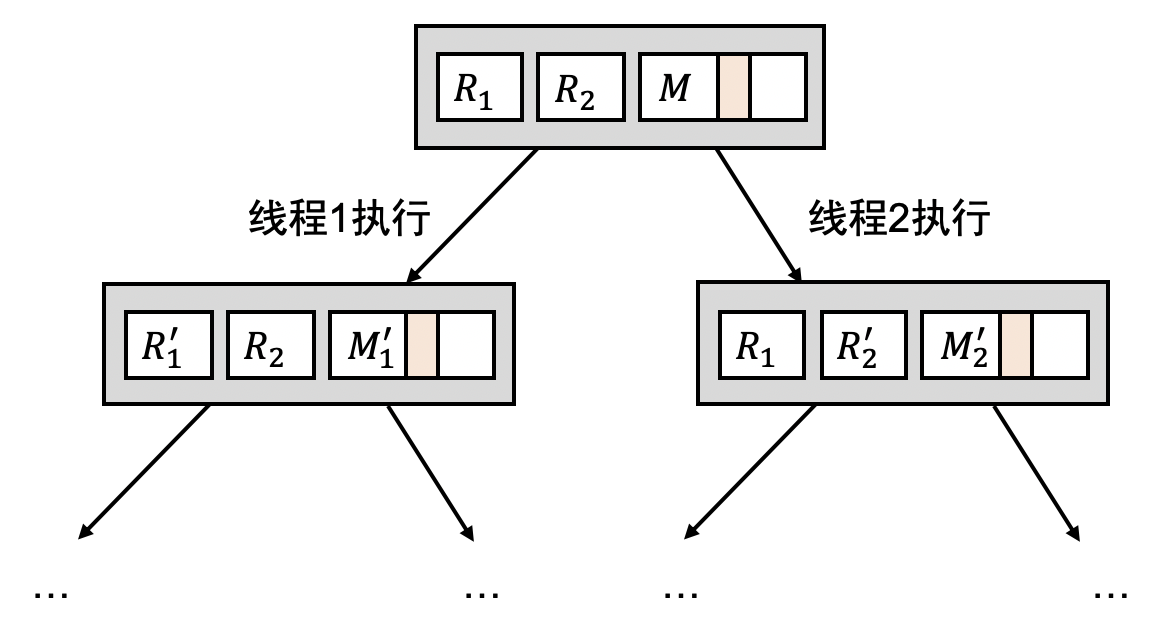
并发程序的状态机模型
并发的基本单位是线程,并发拥有共享内存的多个执行流,共享全部的内存空间,每个执行流拥有独立的堆栈/寄存器
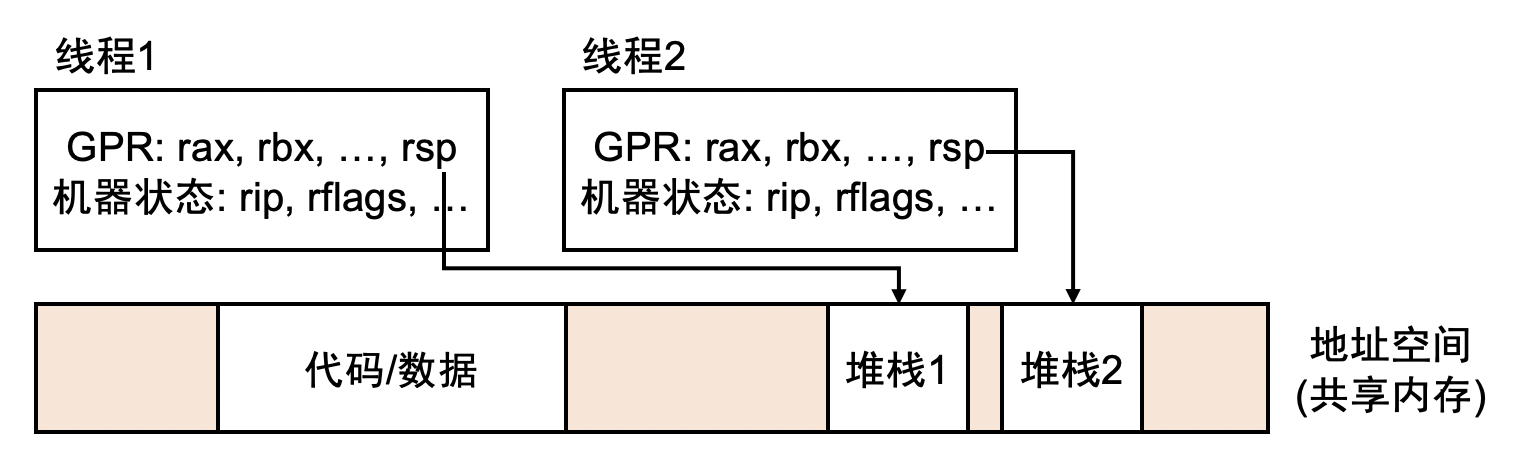
并发程序执行的每一步都是不确定的,其状态机模型如下:
多线程编程
对POSIX线程进行封装,实现一个小型的线程库threads.h
线程的主要数据结构:
struct thread {
int id; // 线程号 从1开始
pthread_t thread; // pthread 线程ID
void (*entry)(int); // 线程的入口函数
struct thread *next; // 链表
};
创建一个线程:
static inline void create(void *fn) {
struct thread *cur = (struct thread *)malloc(sizeof(struct thread));
assert(cur);
cur->id = threads ? threads->id + 1 : 1;
cur->next = threads;
cur->entry = (void (*)(int))fn;
threads = cur;
pthread_create(&cur->thread, NULL, entry_all, cur);
}
上述流程: malloc分配一个struct thread对象,然后将其插入到链表头部,并设置好id及入口函数,使用pthread_create函数可以真正意义上地创建一个线程
函数定义:
int pthread_create(
pthread_t *thread, // pthread_t指针
const pthread_attr_t *attr, // 线程属性
void *(*start_routine) (void *), // 线程入口函数
void *arg // 传递给线程函数的参数
);
对pthread_create的第3个和第4个参数传入了entry_all和cur,这是一个自定义的、统一的线程函数,当pthread_create创建成功后就会调用这个函数,cur作为参数传递,是truct thread结构类型。
定义了一个统一的线程入口函数:
static inline void *entry_all(void *arg) {
struct thread *thread = (struct thread *)arg;
thread->entry(thread->id); // 执行真正的线程任务
return NULL;
}
最后定义了一个join_all函数:
void join(void (*fn)()) {
join_fn = fn;
}
__attribute__((destructor)) void join_all() {
for (struct thread *next; threads; threads = next) {
pthread_join(threads->thread, NULL);
next = threads->next;
free(threads);
}
join_fn ? join_fn() : (void)0;
}
join_all函数的作用是等待所有线程结束,内部封装了一个pthread_join函数,该函数的作用就是等待指定的线程结束,那么就是遍历整个链表,对每个线程使用pthread_join,当线程结束后则释放内存空间。
完整代码:
#include <stdlib.h>
#include <stdio.h>
#include <assert.h>
#include <pthread.h>
struct thread
{
int id;
pthread_t thread;
void (*entry)(int);
struct thread *next;
};
struct thread *threads;
void (*join_fn)();
__attribute__((destructor)) static void join_all()
{
for (struct thread *next; threads; threads = next)
{
pthread_join(threads->thread, NULL);
next = threads->next;
free(threads);
}
join_fn ? join_fn() : (void)0;
}
static inline void *entry_all(void *arg)
{
struct thread *thread = (struct thread *)arg;
thread->entry(thread->id);
return NULL;
}
static inline void create(void *fn)
{
struct thread *cur = (struct thread *)malloc(sizeof(struct thread));
assert(cur);
cur->id = threads ? threads->id + 1 : 1;
cur->next = threads;
cur->entry = (void (*)(int))fn;
threads = cur;
pthread_create(&cur->thread, NULL, entry_all, cur);
}
static inline void join(void (*fn)())
{
join_fn = fn;
}
写一个程序来调用这个库:
#include <threads.h>
void f() {
static int x = 0;
printf("Hello from thread #%d\n", x++);
while (1); // make sure we're not just sequentially calling f()
}
int main() {
for (int i = 0; i < 1000; i++) {
create(f);
}
join(NULL);
}
上述代码创建了1000个线程,并打印一行语句,最后用join等待所有线程结束,这一过程就像从主线程分叉出一堆执行路径,然后等它们都执行完后汇聚在一起:
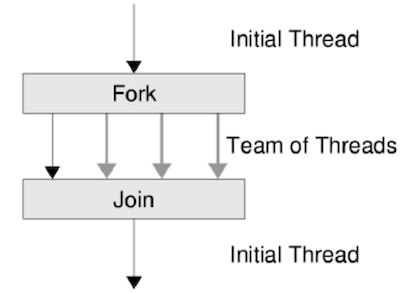
使用gcc编译该代码(末尾加上-lpthread)后运行:
$ ./demo
Hello from thread #0
Hello from thread #3
Hello from thread #1
Hello from thread #5
Hello from thread #4
Hello from thread #7
Hello from thread #2
Hello from thread #9
Hello from thread #8
Hello from thread #10
Hello from thread #6
Hello from thread #11
Hello from thread #12
Hello from thread #13
Hello from thread #14
...
Hello from thread #957
Hello from thread #958
Hello from thread #127
Hello from thread #130
Hello from thread #129
Hello from thread #961
Hello from thread #962
Hello from thread #134
Hello from thread #964
Hello from thread #965
Hello from thread #966
Hello from thread #967
Hello from thread #120
Hello from thread #140
Hello from thread #969
运行该程序后执行top命令
top - 13:24:15 up 41 min, 1 user, load average: 200.16, 51.62, 32.26
Tasks: 390 total, 1 running, 388 sleeping, 0 stopped, 1 zombie
%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 15867.7 total, 9589.0 free, 2826.0 used, 3452.7 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 12250.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10784 hwx 20 0 8264448 9452 1240 S 1594 0.1 1:23.66 demo
2467 hwx 20 0 661868 118848 76844 S 1.7 0.7 1:50.82 Xorg
2604 hwx 20 0 4682468 303284 117188 S 1.7 1.9 1:56.70 gnome-s+
5275 hwx 20 0 826304 55852 41264 S 0.7 0.3 0:10.55 gnome-t+
10761 hwx 20 0 15200 4364 3580 R 0.3 0.0 0:00.04 top
1 root 20 0 168692 11788 8312 S 0.0 0.1 0:01.06 systemd
.....
发现这个进程的CPU占用率高达惊人的1594%,这是并发程序才能做出来的事
运行上述程序后可以确认一些事情:
- x这个变量是共享的,首先它是被定义在静态区的,并且每个线程都可以访问这个变量
- 线程是并发/并行的,如果是串行的话,遇到while(1)就会进入死循环
独立的堆和栈
上述程序已经体现了线程之间可以共享内存,下面这个例子将展现线程栈的一些特点:
#include "threads.h"
__thread char *base,*cur;
__thread int id;
__attribute__((noinline)) void set_cur(void *ptr) {cur = ptr;}
__attribute__((noinline)) char *get_cur() {return cur;}
void stackoverflow(int n) {
set_cur(&n);
if (n % 1024 == 0) {
int size = base - get_cur();
printf("Stack size of T%d >= %d KB\n",id,size/1024);
}
stackoverflow(n+1);
}
void Tprobe(int tid) {
id = tid;
base = (void*)&tid;
stackoverflow(0);
}
int main() {
setbuf(stdout,NULL);
for (int i=0;i<4;i++) {
create(Tprobe);
}
return 0;
}
在GCC编译环境中,可以使用__thread关键字来声明TLS(线程局部存储)变量,这意味着这样的变量不能被各个线程共享,__attribute__((noinline))告知编译器该函数为非内联函数
Trobe函数作为一个线程函数,在该函数中将其参数tid取了地址,赋值给了base,这一步操作的目的是用TLS变量base记下当前函数栈帧的地址(整个递归的起始栈帧),之后调用了stackoverflow函数,stackoverflow中会刷新cur变量,cur即当前函数栈帧的地址,将这个地址与base作差,近似求得当前栈的增长量,接着再次调用自身,进行无休止的递归,直到栈增长到极限
在main函数中开启了4个线程
运行结果
$ ./demo
Stack size of T1 >= 0 KB
Stack size of T3 >= 0 KB
Stack size of T2 >= 0 KB
Stack size of T1 >= 64 KB
Stack size of T4 >= 0 KB
Stack size of T3 >= 64 KB
Stack size of T1 >= 128 KB
Stack size of T2 >= 64 KB
Stack size of T4 >= 64 KB
Stack size of T3 >= 128 KB
....
Stack size of T2 >= 7744 KB
Stack size of T1 >= 8128 KB
Stack size of T3 >= 8064 KB
Stack size of T4 >= 7936 KB
Stack size of T2 >= 7808 KB
Stack size of T3 >= 8128 KB
Stack size of T4 >= 8000 KB
Stack size of T2 >= 7872 KB
Segmentation fault (core dumped)
最后一行是段错误,因为栈达到了极限,可以看到T3最后中止时,栈的大小为8128 KB以上,那么可以推测出一个线程栈的大小是8192KB
操作系统: 数据竞争
多个线程共享内存,因此对共享变量的访问就会形成 “竞争” (races),这是并发编程的一大难题。对处理器系统中线程的代码可能同时进行,比如两个线程同时执行x++就引发了数据竞争,例如下方代码:
#include "threads.h"
#define n 100000000
long sum = 0;
void do_sum() {
for (int i=0;i<n;i++)
sum++;
}
void print() {
printf("sum = %ld\n",sum);
}
int main(void)
{
create(do_sum);
create(do_sum);
join(print);
}
该程序开启了两个线程,每个线程都对sum加n次,串行执行的话应该得到sum的值为2*n,但是:
$ gcc demo.c -o demo -lpthread && ./demo
sum = 104170281
得到了一个这样的不正确的结果
这是原子性的丧失,程序在多处理器系统上不能独占处理器执行,线程是并行执行的,那么要实现互斥和原子性是一个很重要的事情
编译器: 顺序丧失
编译器只考虑程序在一个线程 (处理器) 上执行的顺序语义
采用编译器优化上述程序:
$ gcc -O1 demo.c -o demo -lpthread && ./demo
sum = 100000000
$ gcc -O2 demo.c -o demo -lpthread && ./demo
sum = 200000000
显而易见,两次得到的结果不一样
将程序反汇编,来探究其原因:
$ gcc -O1 demo.c -o demo -lpthread && objdump -d -M intel demo
...
0000000000001203 <do_sum>:
1203: f3 0f 1e fa endbr64
1207: 48 8b 15 0a 2e 00 00 mov rdx,QWORD PTR [rip+0x2e0a] # 4018 <sum>
120e: b8 00 e1 f5 05 mov eax,0x5f5e100
1213: 83 e8 01 sub eax,0x1
1216: 75 fb jne 1213 <do_sum+0x10>
1218: 48 8d 82 00 e1 f5 05 lea rax,[rdx+0x5f5e100]
121f: 48 89 05 f2 2d 00 00 mov QWORD PTR [rip+0x2df2],rax # 4018 <sum>
1226: c3 ret
...
0000000000001314 <main>:
1314: f3 0f 1e fa endbr64
1318: 48 83 ec 08 sub rsp,0x8
131c: 48 8d 3d e0 fe ff ff lea rdi,[rip+0xfffffffffffffee0] # 1203 <do_sum>
1323: e8 29 ff ff ff call 1251 <create>
1328: 48 8d 3d d4 fe ff ff lea rdi,[rip+0xfffffffffffffed4] # 1203 <do_sum>
132f: e8 1d ff ff ff call 1251 <create>
1334: 48 8d 05 ec fe ff ff lea rax,[rip+0xfffffffffffffeec] # 1227 <print>
133b: 48 89 05 de 2c 00 00 mov QWORD PTR [rip+0x2cde],rax # 4020 <join_fn>
1342: b8 00 00 00 00 mov eax,0x0
1347: 48 83 c4 08 add rsp,0x8
134b: c3 ret
134c: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
...
以上是在O1优化下的汇编码
$ gcc -O2 demo.c -o demo -lpthread && objdump -d -M intel demo
...
00000000000012a0 <do_sum>:
12a0: f3 0f 1e fa endbr64
12a4: 48 81 05 69 2d 00 00 add QWORD PTR [rip+0x2d69],0x5f5e100 # 4018 <sum>
12ab: 00 e1 f5 05
12af: c3 ret
...
0000000000001160 <main>:
1160: f3 0f 1e fa endbr64
1164: 48 83 ec 08 sub rsp,0x8
1168: e8 63 01 00 00 call 12d0 <create.constprop.0>
116d: e8 5e 01 00 00 call 12d0 <create.constprop.0>
1172: 48 8d 05 37 01 00 00 lea rax,[rip+0x137] # 12b0 <print>
1179: 48 89 05 a0 2e 00 00 mov QWORD PTR [rip+0x2ea0],rax # 4020 <join_fn>
1180: 31 c0 xor eax,eax
1182: 48 83 c4 08 add rsp,0x8
1186: c3 ret
1187: 66 0f 1f 84 00 00 00 nop WORD PTR [rax+rax*1+0x0]
118e: 00 00
...
以上是在O2优化下的汇编码
比较一下do_sum函数就可以看到区别,可以简要概括:
-O1: R[eax] = sum; R[eax] += N; sum = R[eax]
-O2: sum += N
启动 O1 后,sum 的求和被提出了循环,循环内除了第一次读和最后一次写 sum之外,其他操作都是冗余的,因此第一次读和最后一次写被移动到了循环外面,其他读写都被删除。删除后,n 个加一也被合并成一个加 n。在 O1 优化下,循环变量 i 并没有被优化,依然被保留了,-O1 不会 “删除” 程序中的任何一个定义的变量,这样既得到优化的结果,又不至于使调试太困难,于是可以看到一个空循环(1213-1216)...
如下是对应的C语言代码:
void f_O1()
{
int t = R(sum);
for (int i = 0; i < N; i++);
t += N;
W(sum, t);
}
在 O2 优化下,求和的循环被彻底删除了,被优化成了 “最优” 的代码,一次读内存、一次加法、一次写内存。此时,f_O2 的执行时间非常短,它们并发的可能性也极低 (但理论上仍可能不正确,且在实际的处理器中能够观测到,因为 add 指令在处理器上的实现并不是原子的),所以看到了貌似正确的结果。
如下是对于的C语言代码:
void f_O2()
{
int t = R(sum);
t += N;
W(sum, t);
}
在《深入理解计算机系统》的5.4节,可以了解编译器对循环进行优化的操作
综上所述,,编译器优化更改了程序的执行顺序,甚至移动了代码,这使得原本用作线程同步的共享内存变得失效,这便是顺序性的丧失
多核处理器: 读写可见性
先埋个坑,后续在补充...
标签:00,多处理器,操作系统,thread,void,编程,线程,Hello,cur 来源: https://www.cnblogs.com/N3ptune/p/16441580.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。