标签:分析 HashMap after header 源码 Entry LinkedHashMap before
分析
LinkedHashMap是HashMap的子类,也就是说它与HashMap具有相同存储结构,不同的是,LinkedHashMap加入了一个双向循环链表,链表的头结点是一个不保存数据的head节点。
/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header;
HashMap中Entry有一个指向下一个Entry的next属性,形成了一个单向链表。而LinkedHashMap中继承了HashMap的Entry,多了before和after:
/**
* LinkedHashMap entry.
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
}
链表的形成过程如下图所示:
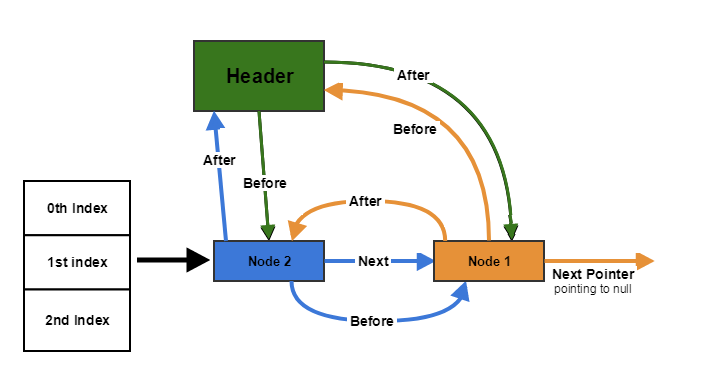
- 初始的时候,head 的 before 和 after 都指向自己
- put 时,将新元素添加到链表末尾,这时候各自的 before 和 after 该如何指向,看图说话
- remove 时同理
知道这个双向循环链表的形成过程,再看源码就简单许多
package java.util;
import java.io.*;
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
private static final long serialVersionUID = 3801124242820219131L;
/**
* 双线链表的头结点(空节点)
*/
private transient Entry<K,V> header;
/**
* 是否根据访问顺序排序
* 默认false,根据插入顺序排序
* true 时,根据访问(put修改或get)顺序排序
*/
private final boolean accessOrder;
/**
* 构造:容量 加载因子
* accessOrder = false;
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
/**
* 构造:容量
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
/**
* 构造方法:可指定accessOrder
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* 初始化 head 节点,这个方法在 HashMap 是空实现
* head 节点不存储任何内容
* head 的 after 和 before 都指向自己
*/
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
/**
* 重写 transfer 方法
* transfer 作用是 rehash,在 HashMap 中是循环数组然后链表
* LinkedHashMap 中是直接循环双向链表,性能更加
*/
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
/**
* 是否包含value,循环双向列表
*/
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
/**
* 与 HashMap 中不同的是,如果accessOrder,也就是按访问顺序,那么将当前节点放到链表的末尾
*/
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
/**
* 清楚还是和 HashMap 一样,只不过要对双向链表做处理,就是回到了初始状态
* header 节点的 before 和 after 都指向自己
*/
public void clear() {
super.clear();
header.before = header.after = header;
}
/**
* LinkedHashMap entry.
* 继承自 HashMap.Entry<K,V>
* 多了 before after 属性,双向循环列表的关键
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
/**
* 新增方法,用于删除双向列表节点
* 看上图自己体会,再看代码
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* 在指定节点前插入节点,同样看图
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* 这个方法在 HashMap.Entry<K,V> 中是空实现,这里重写
* 如果是访问顺序,那么移除双向列表中当前节点,添加到列表末尾,也就是 header 节点前面
* 如果是默认,也就是插入顺序,啥也不干
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
// LinkedHashMap 抽象迭代器,没有实现 next() 方法
private abstract class LinkedHashIterator<T> implements Iterator<T> {
// nextEntry 初始为 header 下一个节点
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
// 快速失败标志
int expectedModCount = modCount;
// 迭代结束判断,下一个节点是 header 节点
public boolean hasNext() {
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
// 获取下一个节点
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
// key 迭代器
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
// value 迭代器
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
// entry 迭代器
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}
Iterator<K> newKeyIterator() { return new KeyIterator(); }
Iterator<V> newValueIterator() { return new ValueIterator(); }
Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); }
/**
* 添加节点,重写 HashMap 中的 addEntry()
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// 删除最老节点,也就是 header 的下一个节点
// 默认返回 false,不删除
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 添加到双向列表末尾
e.addBefore(header);
size++;
}
/**
* 默认返回 false,你可以自己重写它
* 比如 map 快满的时候,删除最老的节点
*
* 下面这例子是 jdk 源码该方法注释中的例子
* <pre>
* private static final int MAX_ENTRIES = 100;
*
* protected boolean removeEldestEntry(Map.Entry eldest) {
* return size() > MAX_ENTRIES;
* }
* </pre>
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
总结
- LinkedHashMap 数据存储和 HashMap 一样,数组+链表
- LinkedHashMap 的 Entry 继承自 HashMap.Entry<K, V>,多了 before 和 after 属性,用于形成双向循环链表
- 插入的时候添加到双向列表的末尾
- 迭代的时候是循环双向列表,而不是跟HashMap一样循环数组+链表,这样效率更高
- 多了访问顺序,默认是按插入顺序,如果是按访问顺序,那么每次put(修改) 和 get 的算一次访问,这时候就把该节点放到双向列表末尾
标签:分析,HashMap,after,header,源码,Entry,LinkedHashMap,before 来源: https://www.cnblogs.com/tailife/p/16359202.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。