标签:c# 精讲 List int 数组 new 序列化 属性
目录- 数组与集合的概念
- Array,ArrayList and List
- 键值对集合
- HashSet
- Json解析
- LICENSE
本文内容来自我写的开源电子书《WoW C#》,现在正在编写中,可以去WOW-Csharp/学习路径总结.md at master · sogeisetsu/WOW-Csharp (github.com)来查看编写进度。预计2021年年底会完成编写,2022年2月之前会完成所有的校对和转制电子书工作,争取能够在2022年将此书上架亚马逊。编写此书的目的是因为目前.NET市场相对低迷,很多优秀的书都是基于.NET framework框架编写的,与现在的.NET 6相差太大,正规的.NET 5学习教程现在几乎只有MSDN,可是MSDN虽然准确优美但是太过琐碎,没有过阅读开发文档的同学容易一头雾水,于是,我就编写了基于.NET 5的《WoW C#》。本人水平有限,欢迎大家去本书的开源仓库sogeisetsu/WOW-Csharp关注、批评、建议和指导。
数组与集合的概念
数组是一种指定长度和数据类型的对象,在实际应用中有一定的局限性。
集合正是为这种局限性而生的,集合的长度能根据需要更改,也允许存放任何数据类型的值。
Array,ArrayList and List<T>
Array、ArrayList和List都是从IList派生出来的,它们都实现了IEnumerable接口
从某种意义上来说,ArrayList和List属于集合的范畴,因为他们都来自程序集System.Collections,但是因为它们都是储存了多个变量的数据结构,并且都不是类似键值对的组合,并且没有先进先出或者先进后出的机制,故而称为数组。
我们一般称呼Array,ArrayList and List<T>为数组。
Array
Array必须在定义且不初始化赋值的时候(不初始化的情况下声明数组变量除外)必须定义数组最外侧的长度。比如:
int[] vs = new int[10];
int[,] duoWei = new int[3, 4];
int[][] jiaoCuo = new int[3][]; // 该数组是由三个一维数组组成的
一维数组
定义
用类似于这种方式定义一个数组
int[] array = new int[5];
初始化赋值
用类似于这种方式初始化
int[] array1 = new int[] { 1, 3, 5, 7, 9 };
也可以进行隐式初始化
int[] array2 = { 1, 3, 5, 7, 9 };
string[] weekDays2 = { "Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat" };
用类似于下面这种方式先声明,再赋值
int[] array3;
array3 = new int[] { 1, 3, 5, 7, 9 }; // OK
//array3 = {1, 3, 5, 7, 9}; // Error
多维数组
数组可具有多个维度。多维数组的每个元素是声明时的数组所属类型的元素。比如说int[,]的每个元素都是int类型而不是int[]类型。换种说法就是多维数组不能算做“数组组成的数组”。
定义
用类似下面这种方式声明一个二维数组的长度
int[,] array = new int[4, 2];
初始化赋值
用类似于下面的方式初始化多维数组:
// Two-dimensional array.
int[,] array2D = new int[,] { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
// The same array with dimensions specified.
int[,] array2Da = new int[4, 2] { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
// A similar array with string elements.
string[,] array2Db = new string[3, 2] { { "one", "two" }, { "three", "four" },
{ "five", "six" } };
// Three-dimensional array.
int[,,] array3D = new int[,,] { { { 1, 2, 3 }, { 4, 5, 6 } },
{ { 7, 8, 9 }, { 10, 11, 12 } } };
还可在不指定级别的情况下初始化数组
int[,] array4 = { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
不初始化的情况下声明数组变量:
int[,] array5;
array5 = new int[,] { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } }; // OK
//array5 = {{1,2}, {3,4}, {5,6}, {7,8}}; // Error
元素赋值和获取元素
可以用类似于array[1,2]的方式来获取数组的值和为数组赋值。
GetLength(0)可以获取最外围数组的长度,GetLength(1)可以获得第二层数组的长度。以此类推。为一个二维数组duoWei循环赋值的方式如下:
Console.WriteLine("二维数组赋值");
for (int i = 0; i < duoWei.GetLength(0); i++)
{
for (int j = 0; j < duoWei.GetLength(1); j++)
{
duoWei[i, j] = i + j;
}
}
如何获取二维数组中的元素个数呢?
int[,] array = new int[,] {{1,2,3},{4,5,6},{7,8,9}};//定义一个3行3列的二维数组 int row = array.Rank;//获取维数,这里指行数 int col = array.GetLength(1);//获取指定维度中的元素个数,这里也就是列数了。(0是第一维,1表示的是第二维) int col = array.GetUpperBound(0)+1;//获取指定维度的索引上限,在加上一个1就是总数,这里表示二维数组的行数 int num = array.Length;//获取整个二维数组的长度,即所有元的个数
来源:C#中如何获取一个二维数组的两维长度,即行数和列数?以及多维数组各个维度的长度? - jack_Meng - 博客园 (cnblogs.com)
交错数组
交错数组是一个数组,其元素是数组,大小可能不同。 交错数组有时称为“数组的数组”。
交错数组不初始化就声明的方式如下:
int[][] ccf;
ccf = new int[3][];
交错数组类似于python的多维数组,比较符合人类的直觉,一个交错数组里面包含了多个数组。
定义
可以采用类似下面的方式来声明一个交错数组:
// 定义多维数组要求每个维度的长度都相同 下面定义交错数组
int[][] jiaoCuo = new int[3][]; // 该数组是由三个一维数组组成的
上面声明的数组是具有三个元素的一维数组,其中每个元素都是一维整数数组。
可使用初始化表达式通过值来填充数组元素,这种情况下不需要数组大小。 例如:
jaggedArray[0] = new int[] { 1, 3, 5, 7, 9 };
jaggedArray[1] = new int[] { 0, 2, 4, 6 };
jaggedArray[2] = new int[] { 11, 22 };
初始化赋值
可在声明数组时将其初始化,如:
int[][] jaggedArray2 = new int[][]
{
new int[] { 1, 3, 5, 7, 9 },
new int[] { 0, 2, 4, 6 },
new int[] { 11, 22 }
};
获取元素和单个赋值
可以用类似于jiaoCuo[1][1]来获取单个元素的值,也可以用类似于jiaoCuo[1][1] = 2;来为单个元素赋值。
可以采取类似于下面的方式来进行循环赋值:
Console.WriteLine("交错数组循环赋值");
// 先声明交错数组中每一个数组的长度
for (int i = 0; i < 3; i++)
{
jiaoCuo[i] = new int[i + 1];
}
// 然后对交错数组中的每一个元素赋值
for (int i = 0; i < jiaoCuo.Length; i++)
{
Console.WriteLine($"交错数组的第{i + 1}层");
for (int j = 0; j < jiaoCuo[i].Length; j++)
{
jiaoCuo[i][j] = i + j;
Console.WriteLine(jiaoCuo[i][j]);
}
}
方法和属性
像数组这种储存多个变量的数据结构,最重要的就是增查删改、获取长度和数据类型转换。Array因为数组的特性,长度不可改变,所以增查删改只能有查和改。
改
Array类型用用类似于下面的方式进行改操作:
vs[0] = 12; //一维数组
duoWei[1, 2] = 3; //多维数组
jiaoCuo[1][1] = 2; //交错数组
查
Array类型用类似于下面的方式进行查操作:
int[] vs = new int[10];
vs[0] = 12;
Console.WriteLine(Array.IndexOf(vs, 12)); //0
Console.WriteLine(vs.Contains(12)); // True
获取长度
可以用类似于下面这种方式来获取:
Console.WriteLine(vs.Length);
Console.WriteLine(vs.Count());
交错数组的Length是获取所包含数组的个数,多维数组的Length是获取数组的元素的总个数,多维数组GetLength(0)可以获取最外围数组的长度,GetLength(1)可以获得第二层数组的长度。以此类推。
Array.ConvertAll() 数据类型转换
可以用Array.ConvertAll<TInput,TOutput>(TInput[], Converter<TInput,TOutput>) 来进行数组类型的转换。
参数如下:
array
TInput[]
要转换为目标类型的从零开始的一维 Array。
converter
用于将每个元素从一种类型转换为另一种类型的 Converter。
来源:[Array.ConvertAll(TInput], Converter) 方法 (System) | Microsoft Docs
demo如下:
double[] vs3 = Array.ConvertAll(vs, item => (double)item);
切片
默认状态下只能对一维数组进行切片,或者通过交错数组获取的一维数组也可以进行切片。
切片的方式类似于vs[1..5],表示vs数组从1到5,左闭右开。^1表示-1,即最后一个元素。[^3..^1]表示倒数第三个元素到倒数第一个元素,左闭右开。
获取单个元素和赋值
可以采用下面的方式来获取单个元素和为单个元素单独赋值:
// 一维数组
Console.WriteLine(vs[1]);
vs[1] = 2;
// 多维数组
Console.WriteLine(duoWei[1, 2]);
duoWei[1, 2] = 3;
// 交错数组
Console.WriteLine(jiaoCuo[1][0]);
jiaoCuo[1][0] = 0;
Array.ForEach 循环
System.Array里面也有ForEach方法,这是用于Array的。
demo:
Array.ForEach(vs, item => Console.WriteLine(item));
ArrayList
定义
用类似于下面的三种方式中的任意一种来声明ArrayList:
| ArrayList() | 初始化 ArrayList 类的新实例,该实例为空并且具有默认初始容量。 |
|---|---|
| ArrayList(ICollection) | 初始化 ArrayList 类的新实例,该类包含从指定集合复制的元素,并具有与复制的元素数相同的初始容量。 |
| ArrayList(Int32) | 初始化 ArrayList 类的新实例,该实例为空并且具有指定的初始容量。 |
可以将Arraylist看作是一种长度可以自由变换,可以包含不同数据类型元素的数组。
初始化赋值
可以采用类似于下面的方式来初始化赋值:
ArrayList arrayList1 = new ArrayList() { 12, 334, 3, true };
循环
循环可以用for和foreach。
foreach (var item in arrayList)
{
Console.WriteLine(item);
}
方法和属性
和list<T>类似,但是没有ConvertAll方法。ArrayList本身没有ForEach方法,但是也可以用传统的foreach方法(就像前面提到的ArrayList的循环那样)。
具体的方法和属性请查看List
List<T>
定义
用类似于下面的三种方式中的任意一种来声明List<T>:
| List() | 初始化 List 类的新实例,该实例为空并且具有默认初始容量。 |
|---|---|
| List(IEnumerable) | 初始化 List 类的新实例,该实例包含从指定集合复制的元素并且具有足够的容量来容纳所复制的元素。 |
| List(Int32) | 初始化 List 类的新实例,该实例为空并且具有指定的初始容量。 |
初始化
用类似于下面的方式在声明时初始化:
List<string> listA = new List<string>() { "hello", " ", "wrold" };
循环
List<T>有一个名称为ForEach的方法:
public void ForEach (Action<T> action);
该方法的本质是要对 List 的每个元素执行的 Action 委托。Action 的参数即为List<T>在循环过程中的每个元素。
demo如下:
// 声明
List<string> listA = new List<string>() { "hello", " ", "wrold" };
// 循环
var i = 0;
listA.ForEach(item =>
{
Console.WriteLine($"第{i + 1}个");
Console.WriteLine(item);
i++;
});
方法和属性
从获取长度、增查删改、数据类型转换、切片和循环来解析。其中除了数据类型转换和List<T>类型本身就拥有的ForEach方法外,都适用于ArrayList。
先声明一个List<string>作为演示的基础:
List<string> listA = new List<string>() { "hello", " ", "wrold" };
属性 长度
Count属性可以获取长度
Console.WriteLine(listA.Count);
属性 取值
Console.WriteLine(listA[0]);
增
即增加元素,可以用Add方法:
listA.Add("12");
查
IndexOf获取所在位置,Contains获取是否包含。
Console.WriteLine(listA.IndexOf("12"));
Console.WriteLine(listA.Contains("12"));
删
Remove根据数据删除,RemoveAt根据位置删除。
listA.Remove("12");
listA.RemoveAt(1);
改
可以用类似于listA[1] = "改变";的方式来修改元素内容。
切片
可以用GetRange(int index, int count)来进行切片操作,第一个参数是切片开始的位置,第二个参数是切片的数量,即从index开始往后数几个数。
Console.WriteLine(listA.GetRange(1, 1).Count);
循环
List<T>有一个名称为ForEach的方法,该方法的本质是要对 List 的每个元素执行的 Action 委托。Action 的参数即为List<T>在循环过程中的每个元素。
demo如下:
// 声明
List<string> listA = new List<string>() { "hello", " ", "wrold" };
// 循环
var i = 0;
listA.ForEach(item =>
{
Console.WriteLine($"第{i + 1}个");
Console.WriteLine(item);
i++;
});
数据类型转换
可以用ConvertAll来对数组的数据类型进行转换,这是List<T>自带的方法。System.Array里面也有ConvertAll方法,这是用于Array的。
List<object> listObject = listA.ConvertAll(s => (object)s);
区别
| 成员单一类型 | 长度可变 | 切片友好 | 方法丰富 | 增查删改 | ConvertAll | |
|---|---|---|---|---|---|---|
| 一维数组 | ✔ | ❌ | ✔ | ❌ | 查、改 | ✔ |
| 多维数组 | ✔ | ❌ | ✔ | ❌ | 查、改 | ✔ |
| 交错数组 | ✔ | ❌ | ✔ | ❌ | 查、改 | ✔ |
| ArrayList | ❌ | ✔ | ❌ | ✔ | 增查删改 | ❌ |
List<T> |
✔ | ✔ | ❌ | ✔ | 增查删改 | ✔ |
Array最大的好处就是切片友好,可以使用类似于[1..3]的方式切片,这是比GetRange更加直观的切片方式。List<T>类型可以通过ToArray的方法来转变成Array。
Array,ArrayList and List<T>之间的转换
关于这一部分的demo代码详情可从Array,ArrayList and List之间的转换 · sogeisetsu/Solution1@88f27d6 (github.com)获得。
先分别声明这三种数据类型。
// 声明数组
int[] a = new int[] { 1,3,4,5,656,-1 };
// 声明多维数组
int[,] aD = new int[,] { { 1, 2 }, { 3, 4 } };
// 声明交错数组
int[][] aJ = new int[][] {
new int[]{ 1,2,3},
new int[]{ 1}
};
// 声明ArrayList
ArrayList b = new ArrayList() { 1, 2, 344, "233", true };
// 声明List<T>
List<int> c = new List<int>();
Array转ArrayList
// 数组转ArrayList
ArrayList aToArrayList = new ArrayList(a);
Array转List<T>
List<int> aToList = new List<int>(a);
List<int> aToLista = a.ToList();
List<T>转Array
int[] cToList = c.ToArray();
List<T>转ArrayList
ArrayList cToArrayList = new ArrayList(c);
ArrayList转Array
在转换的过程中,会丢失数据类型的准确度,简单来说就是转换成的Array会变成object
// ArrayList转Array
object[] bToArray = b.ToArray();
这种转换的意义不大,如果转换完之后再强行用Array.ConvertAll方法来进行数据类型的转换,很有可能会出现诸如Unable to cast object of type 'System.String' to type 'System.Int32'.的错误,这是因为ArrayList本身成员就可以不是单一类型。
数组的打印
Array的打印
对于Array的打印,我找到了四种方式,如下:
-
调用
Array.ForEachArray.ForEach(a, item => Console.WriteLine(item)); -
传统
forEachforeach (var item in a) { Console.WriteLine(item); } -
传统
forfor (int i = 0; i < a.Count(); i++) { Console.WriteLine(a[i]); } -
string.JoinConsole.WriteLine(string.Join("\t", a));
ArrayList的打印
ArrayList的打印我知道的就只有传统的for和foreach两种方式。
List<T>的打印
List<T>的打印除了传统的for和foreach两种方式之外,还有List<T>本身自带的foreach:
var i = 0;
listA.ForEach(item =>
{
Console.WriteLine($"第{i + 1}个");
Console.WriteLine(item);
i++;
});
请注意:ArrayList和List<T>均没有string.Join和调用Array.ForEach两种方式来打印数组。
键值对集合
可以用键来访问元素的集合称之为键值对集合,这是一个笔者私自创造的名词,他们属于集合的一部分。在很多时候,我们所所称的集合就是专指键值对集合。键值对集合每一项都有一个键/值对。键用于访问集合中的项目。
HashTable
表示根据键的哈希代码进行组织的键/值对的集合。
Hashtable的Key和Value都是object类型,所以在使用值类型的时候,必然会出现装箱和拆箱的操作。所以性能会比较弱。
构造函数
HashTable的构造函数有很多,具体可以查看Hashtable 类 (System.Collections) | Microsoft Docs
最常见的就是:
Hashtable 对象名 = new Hashtable ();
Hashtable中key-value键值对均为object类型,所以Hashtable可以支持任何类型的keyvalue键值对,任何非 null 对象都可以用作键
用诸如下面这样的方式来将null作为hashtable的一部分,会报System.ArgumentNullException:“Key cannot be null. Arg_ParamName_Name”的错误。
Hashtable hashtable = new Hashtable();
int? a = null;
hashtable.Add(a, "123");
Console.WriteLine(a);
方法和属性
Hashtable 类中常用的属性和方法如下表所示。
| 属性或方法 | 作用 |
|---|---|
| Count | 集合中存放的元素的实际个数 |
| void Add(object key,object value) | 向集合中添加元素 |
| void Remove(object key) | 根据指定的 key 值移除对应的集合元素 |
| void Clear() | 清空集合 |
| ContainsKey (object key) | 判断集合中是否包含指定 key 值的元素 |
| ContainsValue(object value) | 判断集合中是否包含指定 value 值的元素 |
取值
每个元素都是存储在对象中的键/值对 DictionaryEntry 。 键不能为 null ,但值可以为。
可以用类似于集合名.[键]的方式取值。HashTable的每一个元素都是DictionaryEntry类,这个类有两个属性分别是Key和Value,可以获取每一个元素的键和值。因为HashTable是无序排列,所以只能通过foreach来获取DictionaryEntry。
foreach (DictionaryEntry item in hashtable)
{
Console.WriteLine(item);
Console.WriteLine(item.Key);
Console.WriteLine(item.Value);
Console.WriteLine("-=-=-=-=-=-=-=-=-=");
}
不建议使用
Hashtable类进行新的开发。 相反,我们建议使用泛型 Dictionary 类。 有关详细信息,请参阅 GitHub 上 不应使用非泛型集合 。
SortedList
表示键/值对的集合,这些键值对按键排序并可按照键和索引访问。
SortedList有两种,一种是System.Collections.SortedList,一种是System.Collections.Generic.SortedList。后者使用了泛型,成员类型单一,更安全且性能更优秀。
不建议使用
SortedList类进行新的开发。 相反,我们建议使用泛型 System.Collections.Generic.SortedList 类。 有关详细信息,请参阅 GitHub 上 不应使用非泛型集合 。
SortedList对象在内部维护两个用于存储列表元素的数组; 即,一个数组用于存储键,另一个数组用于关联值。 每个元素都是一个可作为对象进行访问的键/值对 DictionaryEntry 。 键不能为 null ,但值可以为。
SortedList 集合中所使用的属性和方法与 Hashtable 比较类似,这里不再赘述。它的特点就是可以用索引来访问。
构造函数
构造函数有很多,可以查看SortedList 类 (System.Collections) | Microsoft Docs。最常用的就是:
SortedList sortedList = new SortedList();
取值
既可以用类似于集合名.[键]的方式取值,也可以用GetKey(Int32)来获取建和用GetByIndex(Int32)来获取值。顺序为加入元素的顺序
for (int i = 0; i < sortedList.Count; i++)
{
Console.WriteLine($"{sortedList.GetKey(i)}\t{sortedList.GetByIndex(i)}");
}
Dictionary
在单线程情况下,是所有集合类型中最快的。简称Dict。
本质上是HsashTable的泛型类。因为Hashtable的Key和Value都是object类型,所以在使用值类型的时候,必然会出现装箱和拆箱的操作,因此性能肯定是不如Dictionary的,在此就不做过多比较了。
只要对象用作中的键 Dictionary ,它就不得以任何影响其哈希值的方式进行更改。 根据字典的相等比较器,中的每个键都 Dictionary 必须是唯一的。 键不能为 null ,但如果其类型为引用类型,则值可以为 TValue 。
构造方法
最常见的构造方法就是下面这个,其他的请参考Dictionary 类 (System.Collections.Generic) | Microsoft Docs
Dictionary<int, string> dictionary = new Dictionary<int, string>();
其他的方法、属性和取值方式和HashTable一致,唯一的区别就是由于 Dictionary 是键和值的集合,因此元素类型不是键的类型或值的类型。 相反,元素类型是 KeyValuePair 键类型和值类型的。而HashTable每个元素都是一个可作为对象进行访问的键/值对 DictionaryEntry。
foreach (KeyValuePair<int, string> item in dictionary)
{
Console.WriteLine($"{item.Key}\t{item.Value}\tover");
}
单线程程序中推荐使用 Dictionary, 有泛型优势, 且读取速度较快, 容量利用更充分。多线程程序中推荐使用 Hashtable, 默认的 Hashtable 允许单线程写入, 多线程读取, 对 Hashtable 进一步调用 Synchronized() 方法可以获得完全线程安全的类型. 而 Dictionary 非线程安全, 必须人为使用 lock 语句进行保护, 效率大减。
区别
| 直接取值方式 | 泛型 | 特点(用途) | 元素类型 | |
|---|---|---|---|---|
| HashTable | 键值对 | 无 | 用于多线程存储键值对 | DictionaryEntry |
| HashSet |
无序,无键值对,无法直接取值。 | 有 | 用于存储不重复的元素,并且高效的进行set操作。 |
泛型类型 |
| SortedList | 键值对、索引 | 无 | 用于有按顺序索引的需求。有泛型需求时可以使用SortedDictionary<TKey,TValue> |
DictionaryEntry |
| Dictionary | 键值对 | 有 | 单线程程序中推荐使用 Dictionary, 有泛型优势, 且读取速度较快, 容量利用更充分。 | KeyValuePair |
互相转换
我认为集合的类型转换意义不大,因为集合的意义就是一个储存数据的引用类型。程序一般在设计之初就已经通过未来可能的使用场景确定了集合的类型。就像一个类有一个int类型的属性,一般不应该在后面使用的时候去把它转为Double。
这里只讲HashTable和Dictionary之间的转换。
像非泛型类和泛型类之间的转换,必须在转换之初就有类型安全的考虑,否则可能出现很多错误。
HashTable 转 Dict
// hashtable 转 Dict
Dictionary<int, int> dictionary = new Dictionary<int, int>();
foreach (DictionaryEntry item in hashtable)
{
dictionary.Add((int)item.Key, (int)item.Value);
}
Dict 转 HashTable
// Dict转Hashtable
Hashtable hashtable1 = new Hashtable(dictionary);
集合的打印
使用传统的foreach可以非常方便地进行打印。在打印的时候需要考虑到不同类型的集合元素类型的不同。虽然var可以帮助我们不用去记忆那些讨厌的类型名称,但是在某些时候IDE会因为使用了var而无法让代码自动提醒功能正常工作。
foreach (var item in dictionary)
{
Console.WriteLine($"key:{item.Key}\tvalue:{item.Value}");
}
建议使用泛型集合
微软官方建议使用泛型集合,因为non-generic collections有Error prone和Less performant的问题,微软提供了用以替换non-generic collections的类,现在摘录如下:
来源:platform-compat/DE0006.md at master · dotnet/platform-compat (github.com)
HashSet<T>
HashSet 是一个优化过的无序集合,提供对元素的高速查找和高性能的set集合操作,而且 HashSet 是在 .NET 3.5 中被引入的,在 System.Collection.Generic 命名空间下。
只要泛型类允许null,HashSet就允许元素为null。
HashSet会在添加元素的过程中自动去除重复的值,并且不会报错。
HashSet类提供高性能的设置操作。 集是不包含重复元素的集合,其元素无特定顺序。
HashSet
a. HashSet
b. HashSet
HashSet
HashSet 只能包含唯一的元素,它的内部结构也为此做了专门的优化,值得注意的是,HashSet 也可以存放单个的 null 值,可以得出这么一个结论:如何你想拥有一个具有唯一值的集合,那么 HashSet 就是你最好的选择,何况它还具有超高的检索性能。
构造函数
比较常见的构造函数就像下面这样,更多的构造函数请看HashSet 类 (System.Collections.Generic) | Microsoft Docs。
HashSet<int> hashSet = new HashSet<int>();
方法和属性
具体的方法和属性请查看HashSet 类 (System.Collections.Generic) | Microsoft Docs。
像常见的clear、remove、add、count之类的方法和属性不再赘述。
HashSet 的 set操作
HashSet
为了方便理解,先画一个图,A和B为两个浅蓝色的正圆,C为A和B的交集。后面会用到这张图里面的内容。
定义两个HashSet,命名为setA和setB,分别代表图中的A和B。
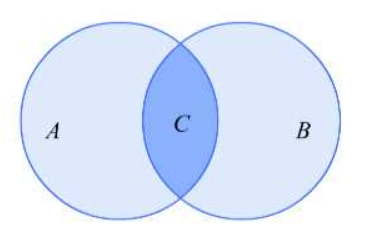
IsProperSubsetOf 真子集
确定 HashSet 对象是否为指定集合的真子集。
// 确定setA是否为setB的真子集
Console.WriteLine(setA.IsProperSubsetOf(setB)); // True
Console.WriteLine(setC.IsProperSubsetOf(setB)); // False
UnionWith 并集
修改当前 HashSet 对象以包含存在于该对象中、指定集合中或两者中的所有元素。其实就是修改当前集合为两个集合的并集。求图中的A+B。
// 求两个的并集
setA.UnionWith(setB);
// 现在setA就是两个集合的并集
foreach (var item in setA)
{
Console.WriteLine(item);
}
IntersectWith 交集
将当前集合变为两个集合的交集,求图中的C。
// 求交集
setA.IntersectWith(setB);
// 现在setA就是两个的交集
foreach (var item in setA)
{
Console.WriteLine(item);
}
ExceptWith 差集
去除交集,从当前 HashSet
// 去除交集,从当前 HashSet<T> 对象中移除指定集合中的所有元素。
setA.ExceptWith(setB);
foreach (var item in setA)
{
Console.WriteLine(item);
}
SymmetricExceptWith
仅包含存在于该对象中或存在于指定集合中的元素(但并非两者)。本质上是(A-C)+(B-C)。
//仅包含存在于该对象中或存在于指定集合中的元素(但并非两者)。
setA.SymmetricExceptWith(setB);
foreach (var item in setA)
{
Console.WriteLine(item);
}
Json解析
json是一种类似于通过键值对来储存数据的格式,在对数据库进行操作的时候,通常会把类数据转为json格式,然后储存在数据库里面,使用的时候再将json转为类的实例化对象。java的springboot框架的一整套解决方案里面可以通过mybatis和fastjson完成这个操作。在web的前后端数据传输中,一般也是用json作为数据的载体,JavaScript有着对json比较完备的支持。
Json格式概述
-
基础
- 概念: JavaScript Object Notation JavaScript对象表示法
-
json现在多用于存储和交换文本信息的语法
-
进行数据的传输
-
JSON 比 XML 更小、更快,更易解析。
-
语法:
-
基本规则
- 数据在名称/值对中:json数据是由键值对构成的 - 键用引号(单双都行)引起来,也可以不使用引号 - 值得取值类型: 1. 数字(整数或浮点数) 2. 字符串(在双引号中) 3. 逻辑值(true 或 false) 4. 数组(在方括号中) {"persons":[{},{}]} 5. 对象(在花括号中) {"address":{"province":"陕西"....}} 6. null - 数据由逗号分隔:多个键值对由逗号分隔 - 花括号保存对象:使用{}定义json 格式 - 方括号保存数组:[]JavaScript获取数据:
-
json对象.键名
-
json对象["键名"]
-
数组对象[索引]
-
遍历

解析
使用 C# 对 JSON 进行序列化和反序列化 - .NET | Microsoft Docs
会用到两个名词,序列化和反序列化,其中序列化是指将实例对象转换成json格式的字符串,反序列化则是逆向前面序列化的过程。
在序列化的过程中,默认情况下会只序列化公共读写的属性,可以通过System.Text.Json.Serialization的JsonInclude特性或者JsonSerializerOptions的IncludeFields属性来包含公有字段。通过System.Text.Json.Serialization的JsonInclude特性可以来自定义可以序列化的非公共属性访问器(即属性的访问修饰符为public,但是set访问器和get访问器的任意一方为非public)。这可能对使用惯了java的人来说不适应,事实上这是一种很合理的序列化要求,默认状况下,序列化器会序列化对象中的所有可读属性,反序列化所有可写属性,这种方式尊重了访问修饰符的作用。也可用开源的Newtonsoft.Json来序列化非公有属性。现在很多编程语言(包括.NET)能通过反射来获取私有属性本身就是不合理的,从.NET core能明显的感觉到.NET团队出于安全的考虑在限制反射的使用。
需要用到的namespace:
using System.Text.Encodings.Web;
using System.Text.Json;
using System.Text.Json.Serialization;
using System.Text.Unicode;
- 用
System.Text.Json的JsonSerializer.Serialize方法可以进行序列化。 - 用
System.Text.Json的JsonSerializer.Deserialize方法可以进行反序列化。 - 用
System.Text.Json.Serialization可以要序列化的类添加必要的特性,比如JsonPropertyName为属性序列化时重命名,再比如JsonInclude来定义序列化时要包含的字段。 - 用
System.Text.Encodings.Web和System.Text.Unicode来让特定的字符集在序列化的时候能够正常序列化而不是被转义成为\uxxxx,其中xxxx为字符的 Unicode 代码。事实上,默认情况下,序列化程序会转义所有非 ASCII 字符。
序列化
只将实例化对象转变成json字符串,假设有一个实例化对象weatherForecast,序列化方式如下:
string jsonString = JsonSerializer.Serialize(weatherForecast);
反序列化
指将json字符串序列化成实例化对象,书接前文,方式如下:
weatherForecast = JsonSerializer.Deserialize<WeatherForecastWithPOCOs>(jsonString);
JsonSerializerOptions
可以通过JsonSerializerOptions来指定诸如是否整齐打印和忽略Null值属性等信息。使用方式为将JsonSerializerOptions实例化之后再当作JsonSerializer.Serialize和JsonSerializer.Deserialize的参数。
关于JsonSerializerOptions的属性可以查看如何使用 System.Text.Json 实例化 JsonSerializerOptions | Microsoft Docs
先实例化一个JsonSerializerOptions对象,在初始化器里面定义各种属性:
JsonSerializerOptions jsonSerializerOptions = new JsonSerializerOptions()
{
// 整齐打印
WriteIndented = true,
// 忽略值为Null的属性
IgnoreNullValues = true,
// 设置Json字符串支持的编码,默认情况下,序列化程序会转义所有非 ASCII 字符。 即,会将它们替换为 \uxxxx,其中 xxxx 为字符的 Unicode
// 代码。 可以通过设置Encoder来让生成的josn字符串不转义指定的字符集而进行序列化 下面指定了基础拉丁字母和中日韩统一表意文字的基础Unicode 块
// (U+4E00-U+9FCC)。 基本涵盖了除使用西里尔字母以外所有西方国家的文字和亚洲中日韩越的文字
Encoder = JavaScriptEncoder.Create(UnicodeRanges.BasicLatin, UnicodeRanges.CjkUnifiedIdeographs),
// 反序列化不区分大小写
PropertyNameCaseInsensitive = true,
// 驼峰命名
PropertyNamingPolicy = JsonNamingPolicy.CamelCase,
// 对字典的键进行驼峰命名
DictionaryKeyPolicy = JsonNamingPolicy.CamelCase,
// 序列化的时候忽略null值属性
DefaultIgnoreCondition = JsonIgnoreCondition.WhenWritingNull,
// 忽略只读属性,因为只读属性只能序列化而不能反序列化,所以在以json为储存数据的介质的时候,序列化只读属性意义不大
IgnoreReadOnlyFields = true,
// 不允许结尾有逗号的不标准json
AllowTrailingCommas = false,
// 不允许有注释的不标准json
ReadCommentHandling = JsonCommentHandling.Disallow,
// 允许在反序列化的时候原本应为数字的字符串(带引号的数字)转为数字
NumberHandling = JsonNumberHandling.AllowReadingFromString,
// 处理循环引用类型,比如Book类里面有一个属性也是Book类
ReferenceHandler = ReferenceHandler.Preserve
};
然后在序列化和反序列化的时候jsonSerializerOptions对象当作参数传给JsonSerializer.Serialize和JsonSerializer.Deserialize:
string jsonBookA = JsonSerializer.Serialize(bookA, jsonSerializerOptions);
// 反序列化
BookA bookA1 = JsonSerializer.Deserialize<BookA>(jsonBookA, jsonSerializerOptions);
JsonSerializerOptions 常用属性概述
| 作用 | 值类型 | |
|---|---|---|
WriteIndented |
整齐打印,将此值设置为true后序列化的json字符串在打印的时候会进行自动缩进和换行。默认为false。 | bool |
IgnoreNullValues |
忽略值为Null的属性。默认为false。 | bool |
Encoder |
设置Json字符串支持的编码,默认情况下,序列化程序会转义所有非 ASCII 字符。 即,会将它们替换为 \uxxxx,其中 xxxx 为字符的 Unicode代码。 可以通过设置Encoder来让生成的josn字符串不转义指定的字符集而进行序列化。可设置为Encoder = JavaScriptEncoder.Create(UnicodeRanges.BasicLatin, UnicodeRanges.CjkUnifiedIdeographs)来包含除使用西里尔字母以外所有西方国家的文字和亚洲中日韩越的文字 |
JavaScriptEncoder |
PropertyNameCaseInsensitive |
反序列化不区分键的大小写。默认为false。 | bool |
PropertyNamingPolicy |
序列化时属性的命名方式,常用的为JsonNamingPolicy.CamelCase设置成小写字母开头的驼峰命名。 |
JsonNamingPolicy |
DictionaryKeyPolicy |
序列化时对字典的string键进行小写字母开头的驼峰驼峰命名。 | JsonNamingPolicy |
DefaultIgnoreCondition |
指定一个条件,用于确定何时在序列化或反序列化过程中忽略具有默认值的属性。 默认值为 Never。常用值为JsonIgnoreCondition.WhenWritingDefault来忽略默认值属性。 |
JsonIgnoreCondition |
IgnoreReadOnlyFields |
序列化时忽略只读属性,因为只读属性只能序列化而不能反序列化,所以在以json为储存数据的介质的时候,序列化只读属性意义不大。默认为false。 | bool |
AllowTrailingCommas |
反序列化时,允许结尾有逗号的不标准json,默认为false。 | bool |
ReadCommentHandling |
反序列化时,允许有注释的不标准json,默认为false。 | bool |
NumberHandling |
使用NumberHandling = JsonNumberHandling.AllowReadingFromString可允许在反序列化的时候原本应为数字的字符串(带引号的数字)转为数字 |
JsonNumberHandling |
ReferenceHandler |
配置在读取和写入 JSON 时如何处理对象引用。使用ReferenceHandler = ReferenceHandler.Preserve仍然会在序列化和反序列化的时候保留引用并处理循环引用。 |
ReferenceHandler |
IncludeFields |
确定是否在序列化和反序列化期间处理字段。 默认值为 false。 |
bool |
System.Text.Json.Serialization 特性
可以为将要序列化和被反序列化而生成的类的属性和字段添加特性。
JsonInclude 包含特定public字段和非公共属性访问器
在序列化或反序列化时,使用 JsonSerializerOptions.IncludeFields 全局设置或 [JsonInclude] 特性来包含字段(必须是public),当应用于某个属性时,指示非公共的 getter 和 setter 可用于序列化和反序列化。 不支持非公共属性。
demo:
/// <summary>
/// 时间戳
/// </summary>
[JsonInclude]
public long timestamp = DateTimeOffset.Now.ToUnixTimeMilliseconds();
/// <summary>
/// 书的名称
/// </summary>
[JsonInclude]
public string Name { private get; set; } = "《书名》";
JsonPropertyName 自定义属性名称
若要设置单个属性的名称,请使用 [JsonPropertyName] 特性。
此特性设置的属性名称:
- 同时适用于两个方向(序列化和反序列化)。
- 优先于属性命名策略。
demo:
/// <summary>
/// 作者
/// </summary>
[JsonPropertyName("作者")]
public string Author
{
get { return _author; }
set { _author = value; }
}
JsonIgnore 忽略单个属性
阻止对属性进行序列化或反序列化。
demo:
/// <summary>
/// 书的出版商
/// </summary>
[JsonIgnore]
public string OutCompany { get => _outCompany; set => _outCompany = value; }
JsonExtensionData 处理溢出 JSON
反序列化时,可能会在 JSON 中收到不是由目标类型的属性表示的数据。可以将这些无法由目标类型的属性表示的数据储存在一个Dictionary<string, JsonElement>字典里面,方式如下:
/// <summary>
/// 储存反序列化时候的溢出数据
/// </summary>
[JsonExtensionData]
public Dictionary<string, JsonElement> ExtensionData { get; set; }
笔者的选择
在笔者的开发经验当中,json用的最多的就是前后端数据传输和数据库储存数据。对jsonSerializerOptions往往会选择这几个选项:
JsonSerializerOptions jsonSerializerOptions = new JsonSerializerOptions()
{
// 整齐打印
WriteIndented = true,
// 忽略值为Null的属性
IgnoreNullValues = true,
// 设置Json字符串支持的编码,默认情况下,序列化程序会转义所有非 ASCII 字符。 即,会将它们替换为 \uxxxx,其中 xxxx 为字符的 Unicode
// 代码。 可以通过设置Encoder来让生成的josn字符串不转义指定的字符集而进行序列化 下面指定了基础拉丁字母和中日韩统一表意文字的基础Unicode 块
// (U+4E00-U+9FCC)。 基本涵盖了除使用西里尔字母以外所有西方国家的文字和亚洲中日韩越的文字
Encoder = JavaScriptEncoder.Create(UnicodeRanges.BasicLatin, UnicodeRanges.CjkUnifiedIdeographs, UnicodeRanges.CjkSymbolsandPunctuation),
// 反序列化不区分大小写
PropertyNameCaseInsensitive = true,
// 驼峰命名
PropertyNamingPolicy = JsonNamingPolicy.CamelCase,
// 对字典的键进行驼峰命名
DictionaryKeyPolicy = JsonNamingPolicy.CamelCase,
// 忽略只读属性,因为只读属性只能序列化而不能反序列化,所以在以json为储存数据的介质的时候,序列化只读属性意义不大
IgnoreReadOnlyFields = true,
// 允许在反序列化的时候原本应为数字的字符串(带引号的数字)转为数字
NumberHandling = JsonNumberHandling.AllowReadingFromString
};
尽量不使用JsonPropertyName特性,对有可能会用到json反序列化的类一定会用到JsonExtensionData特性来储存可能存在的溢出数据。JsonIgnore 和JsonInclude会广泛的使用而不用JsonSerializerOptions的IncludeFields来序列化所有字段。
LICENSE
已将所有引用其他文章之内容清楚明白地标注,其他部分皆为作者劳动成果。对作者劳动成果做以下声明:
copyright © 2021 苏月晟,版权所有。

本作品由苏月晟采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
标签:c#,精讲,List,int,数组,new,序列化,属性 来源: https://www.cnblogs.com/sogeisetsu/p/15618843.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。